Secure RAG for Safe AI Deployments Using F5 Distributed Cloud and NetApp ONTAP
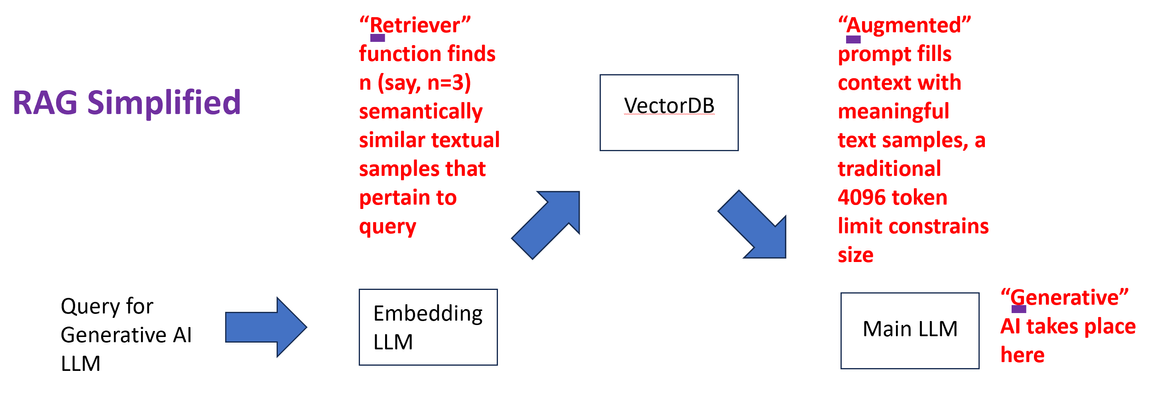
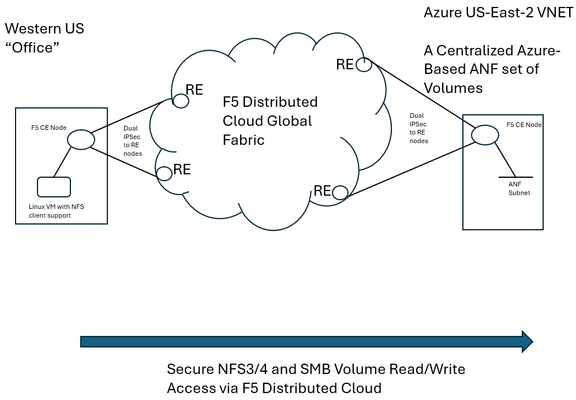
Retrieval Augmented Generation (RAG) is one of the most discussed techniques to empower Large Language Models (LLM) to deliver niche, hyper-focused responses pertaining to specialized, sometimes proprietary, bodies of knowledge documents. Two simple examples might include highly detailed company-specific information distilled from years of financial internal reporting from financial controllers or helpdesk type queries with the LLM harvesting only relevant knowledge base (KB) articles, releases notes, and private engineering documents not normally exposed in their entirety. RAG is highly bantered about in numerous good articles; the two principal values are: LLM responses to prompts (queries) based upon specific, niche knowledge as opposed to the general, vast pre-training generic LLMs are taught with; in fact, it is common to instruct LLMs not to answer specifically with any pre-trained knowledge. Only the content “augmenting” the prompt. Attribution is a key deliverable with RAG. Generally LLM pre-trained knowledge inquiries are difficult to traceback to a root source of truth. Prompts augmented with specific assistive knowledge normally solicit responses that clearly call out the source of the answers provided. Why is the Security of RAG Source Content Particularly Important? To maximize the efficacy of LLM solutions in the realm of artificial intelligence (AI) an often-repeated adage is “garbage in, garbage out” which succinctly states an obvious fact with RAG: valuable and actionable items must be entered into the model to expect valuable, tactical outcomes. This means exposing key forms of data, examples being data which might include patented knowledge, intellectual property not to be exposed in raw form to competitors. Actual trade secrets, which will infuse the LLM but need to remain confidential in their native form. In one example around trade secrets, the Government of Canada spells out a series of items courts will look at in determining compensation for misuse (theft) of intellectual property. It is notable that the first item listed is not the cost associated with creation of the secret material (“the cost in money or time of creating or developing the information”) but rather the very first item is instead how much effort was made to keep the content secure (“the measures taken to maintain secrecy”). With RAG, incoming queries are augmented with rich, semantically similar enterprise content. The content has already been populated into a vector database by converting documents, they might be pdf or docx as examples, into raw text form and converting chunks of text into vectors. The vectors are long sequences of numbers with similar mathematical attributes for similar content. As a trivial example, one-word chunks such as glass, cup, bucket, jar might be semantically related, meaning similarities can be construed by both human minds and LLMs. On the other hand, empathy, joy, and thoughtfulness maintain similarities of their own. This semantic approach means a phrase/sentence/paragraph (chunk) using bow to mean “to bend in respect” will be highly distinct from chunks referring to the “front end of a ship" or “something to tie one’s hair back with”, even a tool every violinist would need. The list goes on; all semantic meanings of bow are very different in these chunks and would have distinctive embeddings within a vector database. The word embedding is likely derived from “fixing” or “planting” an object. In this case, words are “embedded” into a contextual understanding. The typical length of the number sequence describing the meaning of items has typically been more than 700, but this number of “dimensions” applied is always a matter of research, and the entire vector database is arrived at with an embedding LLM, distinct from the main LLM that will produce generative AI responses to our queries. Incoming queries destined for the main generative AI LLM can, in turn, be converted to vectors themselves by the very same text-embedding “helper” LLM and through retrieval (the “R” in RAG) similar textual content can buttress the prompt presented to the main LLM (double click to expand). Since a critical cog in the wheel of the RAG architecture is the ingestion of valuable and sensitive source documents into the vector database, using the embedding LLM, it is not just prudent but critical that this source content be brought securely over networks to the embedding engine. F5 Distributed Cloud Secure Multicloud Networking and NetApp ONTAP For many practical, time-to-market reasons, modern LLMs, both the main and embedding instances, may not be collocated with the data vaults of modern enterprises. LLMs benefit from cloud compute and GPU access, something often in short supply for on-premises production roll outs. A typical approach assisted by the economies of scale might be to harvest public cloud providers, such as Azure, AWS, and Google Cloud Platform for the compute side of AI projects. Azure, as one example, can turn up virtual machines with GPUs from NVIDIA like A100, A2, and Tesla T4 to name a few. The documents needed to feed an effective RAG solution may well be on-premises, and this is unlikely to change for reasons including governance, regulatory, and the weight of decades of sound security practice. One of the leading on-premises storage solutions of the last 25 years is the NetApp ONTAP storage appliance family, and reflected in this quote from NVIDIA: "Nearly half of the files in the world are stored on-prem on NetApp." — Jensen Huang, CEO of NVIDIA A key deliverable of F5 Distributed Cloud is providing encrypted interconnectivity of disparate physical sites and heterogeneous cloud instances such as Azure VNETs or AWS VPCs. As such, there are two immediate, concurrent F5 features that come to mind: Secure interconnectivity of on-premises NetApp volumes (NAS) or LUNs (Block) containing critical documents for ingestion into RAG. Utilize encrypted L3 connectivity between the enterprise location and the cloud instance where the LLM/RAG are instantiated. TCP load balancers are another alternative for volume sharing NAS protocols like NFS or SMB/CIFS. Secure access to the LLM web interface or RESTful API end points, with HTTPS load balancers including key features like WAF, anti-bot mechanisms, and API automatic rate limiting for abusive prompt sources. The following diagram presents the topology this article set out to create, REs are “regional edge” sites maintained internationally by F5 and harness private RE to RE, high-speed global communication links. DNS names, such as the target name of an LLM service, will leverage mappings to anycast IP addresses, thus users entering the RE network from southeast Asian might, for example, enter the Singapore RE while users in Switzerland might enter via a Paris or Frankfurt RE. Complementing the REs are Customer Edge (CE) nodes. There are virtual or physical appliances which act as security demarcation points. For instance, a CE placed in an Azure VNET can protect access to the server supporting the LLM, removing any need for Internet access to the server, which is now entirely accessible only through a private RFC-1918 type of private address. External access to the LLM for just employees or, maybe employees and contractors, or potentially access for the Internet community is enabled by a distributed HTTPS load balancer. In the example depicted above, oriented towards full Internet access, the FQDN of the LLM is projected by the load balancer into the global DNS and consumers of the service resolve the name to one IP address and are attracted to the closest RE by BGP-4’s support for anycast. As the name “distributed” load balancer suggests, the origin pool can be in an entirely different site than the incoming RE, in this case the origin pool is the LLM behind the CE in the Azure VNET. The LLM requests travel from RE to CE via a highspeed networking underlay. The portion of the solution that securely ties the LLM to the source content required for RAG to embed vectors is, in this case, utilizing layer 3 multicloud networking (MCN). The solution is turnkey, routing table are automatically connected to members of the L3 MCN, in this case the inside interfaces of the Azure CE and Redmond, Washington on-premises CE and traffic flows over an encrypted underlay network. As such, the NetApp ONTAP cluster can securely expose volumes with key file ware via a protocol like Network File System (NFS), no risk of data exposure to third-party prying eyes exists. The following diagram drills into the RE and CE and NetApp interplay (double click to expand). F5 Distributed Cloud App Connect and LLM Setup This article speaks to hands-on experience with web-driven LLM inferencing with augmented prompts derived from a RAG implementation. The AI compute was instantiated on an Azure-hosted Ubuntu 20.04 virtual machine with 4 virtual cores. Installed software included Python 3.10, and libraries such as Langchain, Pypdf (for converting pdf documents to text), FAISS (for similarity searching via a vector database), and other libraries. The actual open source LLM utilized for the generative AI is found here on huggingface.co. The binary, which exceeds 4 GB, is considered effective for CPU-based deployments. The embedding LLM model, critical to seed the vector database with entries derived from secured enterprise documentation, and then used again per incoming query for RAG similarity searches to build augmented prompts, was from Hugging Face: sentence-transformers/all-MiniLM-L6-v2 and can be found here. The AI RAG solution was implemented in Python3, and as such the Azure Ubuntu can be accessed both by SSH or via Jupyter Notebooks. The latter was utilized as this is the preferred final delivery mechanism for standard users, not a web chatbot design or the requirement to use API commands through solutions like Postman or Curl. This design choice, to steer the user experience towards Jupyter Notebook consumption, is in keeping with the fact that it has become a standard in AI LLM usage where the LLM is tactical and vital to an enterprise's lines of business (LOBs). Jupyter Notebooks are web-accessed with a browser like Chrome or Edge and as such, F5’s WAF, anti-bot, and L7 DDoS, all part of the F5 WAAP offering, can easily be laid upon an HTTP load balancer with a few mouse clicks in XC to provide premium security to the user experience. NetApp and F5 Distributed Cloud Secure Multicloud Networking The secure access to files for ingestion into the vector database, for similarity searches when user queries are received, makes use of an encrypted L3 Multicloud Network relationship between the Azure VNET and the LAN on prem in Redmond, Washington hosting the NetApp ONTAP cluster. The specific protocol chosen was NFS and the simplicity is demonstrated by the use of one Linux command to present key, high-valued documents for the AI steps to populate the database: #mount -t nfs <IP Address of NetAPP LIF interface on-prem>:/Secure_docs_for_RAG /home/ubuntu_restriced_user/rag_project/docs/Secure_docs_for_RAG. This address is available nowhere else in the world except behind this F5 CE in the Azure VNET. After the pdf files are converted to text, chunked to reasonable sizes with some overlap suggested between the end of one chunk and the start of the next chunk, the embedding LLM will populate the vector database. The files are always only accessed remotely by NFS through the mounted volume, and this mount may be terminated until new documents are ready to be added to the solution. The Objective RAG Implementation - Described In order to have a reasonable facsimile of the real-word use cases this solution will empower today, but not having any sensitive documents to be injected, it was decided to use some seminal “Internet Boom”-era IETF Requests for Comment (RFCs) as source content. With the rise of multi-port routing and switching devices, it became apparent the industry badly needed specific and highly precise definitions around network device (router and switch) performance benchmarking to allow purchasers “apples-to-apples” comparisons. These documents recommend testing parameters, such as what frame or packet sizes to test with, test iteration time lengths, when to use FIFO vs LIFO vs LILO definitions of latency, etc. RFC-1242 (Request for Comment, terminology) and RFC-2544 (methodologies), chaired by Scott Bradner of Harvard University, and the later RFC 2285 (LAN switching terminologies), chaired by Bob Mandeville then of European Network Laboratories are three prominent examples, to which test and measurement solutions aspired to be compliant. Detailed LLM answers for quality assurance engineers in the network equipment manufacturing (NEM) space is the intended use case of the design, answers that must be distilled specifically by generative AI considering queries augmented by RAG and specifically only based upon these industry-approved documents. These documents are, of course, not containing trade secrets or patented engineering designs. They are in fact publicly available from the IETF, however they are nicely representative of the value offered in sensitive environments. Validating RAG – Watching the Context Provided to the LLM To ensure RAG was working, the content being augmented in the prompt was displayed to screen, we would expect to see relevant clauses and sentences from the RFCs being provided to the generative AI LLM. Also, if we were to start by asking questions that were outside the purview of this testing/benchmarking topic, we should see the LLM struggle to provide users a meaningful answer. To achieve this, rather than, say, asking what 802.3/Ethernetv2 frame sizes should be used in throughput measurements, and what precisely is the industry standard definition of the term “throughput” was, the question instead pertained to a recent Netflix release, featuring Lindsay Lohan. Due to the recency of the film, even if the LLM leaned upon its pretrained model, it will come up with nothing meaningful. “Question: Important, only use information provided as context in the prompt, do not use other trained knowledge. Please identify who played Heather in the March 2024 Lindsay Lohan Netflix movie titled Irish Wish?” As seen in the following Jupyter screenshot, the RAG solution can only provide augmented prompts from the database, in this case it has some test and measurement clauses and some rules pertaining to the winter ice sport of curling (double click to enlarge). The supportive context data augmenting the prompt was, as expected, not going to help in this off-the-wall query, as only the RFCs and some sports rules had been introduced to the vector database. What is especially noteworthy is the LLM did not simply admit it could not possibly answer this question but hallucinated a very articulate response that indicated “Heather played for her team against Lindsay Lohan’s Team Ireland”. To validate the RAG architecture for a working scenario, actually pertinent to the movie, a film review in pdf format was added to the ONTAP cluster-housed volume. The supportive documentation was consumed (using Pypdf from the Jupyter Notebook it became text). It was automatically chunked and introduced to the FAISS vector database through the Hugging Face embedding LLM. With the RAG vector database populated by the embedding LLM, the responses then became meaningful. The following exchange shows the value of RAG in producing meaningful, thought-out answers: Question: Important, only use information provided as context in the prompt, do not use other pre-trained knowledge. Who does Maddie edit novels for in the Lindsay Lohan March 2024 Netflix movie titled Irish Wish? Answer: Let's think step by step. We know that Maddie Kelly plays a book editor who harbors a big secret, and we have been given information about her job as an editor for Paul Kennedy (played by Alexander Vlahos), which is also part of the question context provided above. Therefore it seems logical to infer that she edits novels in general but specifically those written or co-written by author Paul Kennedy - who happens to be a bestselling romance novelist as stated earlier on, so we can safely conclude Maddie works for Paul himself (as opposed to any other book publishing company). This time we see relevant, meaningful context provided by RAG, with relevant portions of the pdf file review document augmenting the prompt. The augmentations are normally not displayed unless requested by the user or programmer, unlike humans, LLMs do not require superfluous text formatting (advantage: LLMs) and thus the content is packed tightly and efficiently. Fewer characters also mean fewer tokens get used by the targeted AI model and can allow more data before a token context limit is reached. In pay-for-use LLM approaches fewer tokens also help the enterprise’s bottom line financially. Also, note that the answer will likely not always be identical with subsequent asks of the same question as per LLM normal behavior. Features like “temperature setting” can also allow more “creative” ideas in responses, injecting humor and even outlandishness if desired. The RAG workflow is now validated, but the LLMs in question (embedding and main generative LLM) can still be made better with these suggestions: Increase “chunk” sizes so ideas are not lost when excessive breaks make for short chunks. Increase “overlap” so an idea/concept is not lost at the demarcation point of two chunks. Most importantly, provide more context from the vector database as context lengths (maximum tokens in a request/response) are generally increasing in size. Llama2, for instance, typically has a 4,096 context length but can now be used with larger values, such as 32,768. This article used only 3 augmentations to the user query, better results could be attained by increasing this value at a potential cost of more CPU cycles. Using Secure RAG – F5 L3 MCN, HTTPS Load Balancers and NetApp ONTAP Together With the RAG architecture validated to be working, the solution was used to assist the target user entering queries to the Azure server by means of Jupyter Notebooks, with RAG documents ingested over encrypted, private networking to the on-premises ONTAP cluster NFS volumes. The questions posed, which are answerable by reading and understanding key portions spread throughout the Scott Bradner RFCs, was: “Important, only use information provided as context in the prompt, do not use other pre-trained knowledge. Please explain the specific definition of throughput? What 802.3 frame sizes should be used for benchmarking? How long should each test iteration last? If you cannot answer the questions exclusively with the details included in the prompt, simply say you are unable to answer the question accurately. Thank you." The Jupyter Notebook representation of this query, which is made in the Python language and issued from the user’s local browser anywhere in the world and directly against the Azure-hosted LLM, looks like the following (click to expand image): The next screenshot demonstrates the result, based upon the provided secure documents (double click to expand). The response is decent, however, the fact that it is clearly using the provided augmentations to the prompt, that is the key objective of this article. The accuracy of the response can be questionable in some areas, the Bradner RFCs highlighted the importance of 64-byte 802.3/Ethernetv2 frame sizes in testing, as line rate forwarding with this minimum size produces the highest theoretically possible frame per second load. In the era of software driven forwarding in switches and routers this was very demanding. Sixty-four byte frames result in 14,881 fps (frames per second) for 10BaseT, 148,809 fps for 100BaseT, 1.48 million fps for Gigabit Ethernet. These values were frequently more aspirational in earlier times and also a frequent metric used in network equipment purchasing cycles. Suspiciously, the LLM response calls out 64kB in 802.3 testing, not 64B, something which seems to be an error. Again, with this architecture, the actual LLM providing the generative AI responses is increasingly viewed as a commodity, alternative LLMs can be plugged quickly and easily into the RAG approach of this Jupyter Notebook. The end user, and thus the enterprise itself, is empowered to utilize both different LLMs, purchased or open-source from sites like Hugging Face, to determine optimal results. The other key change that can affect the overall accuracy of results is to experiment with different embedding models. In fact, there are on-line “leader” boards strictly for embedding LLMs so one can quickly swap in and out various popular embedding LLMs to see the impact on results. Summary and Conclusions on F5 and NetApp as Enablers for Secure RAG This article demonstrated an approach to AI usage that leveraged the compute and GPU availability that can be found today within cloud providers such as Azure. To safely access such an AI platform for a production-grade enterprise requirement, F5 Distributed Cloud (XC) provided HTTPS load balancers to connect worker browsers to a Jupyter Notebook service on the AI platform, this service applies advanced security upon the traffic within the XC, from WAF to anti-bot to L3/L7 DDOS protections. Utilizing secure Multicloud Networking (MCN), F5 provided a private L3 connectivity service between the inside interface on an Azure VNET-based CE (customer edge) node and the inside interface of an on-premises CE node in a building in Redmond, Washington. This secure network facilitated an NFS remote volume, content on spindles/flash in on-premises NetApp ONTAP to be remotely mounted on the Azure server. This secure file access provided peace of mind to exposing potentially critical and private materials from NetApp ONTAP volumes to the AI offering. RAG was configured and files were ingested, populating a vector database within the Azure server, that allowed details, ideas, and recommendations to be harnessed by a generative AI LLM by augmenting user prompts with text gleaned from the vector database. Simple examples were used to first demonstrate that RAG was working by posing queries that should not have been addressed by the loaded secure content; such a query was not suitably answered as expected. The feeding of meaningful content from ONTAP was then demonstrated to unleash the potential of AI to address queries based upon meaningful .pdf files. Opportunities to improve results by swapping in and out the main generative AI model, as well as the embedding model, were also considered.403Views1like0CommentsDistributed Cloud Support for NAS Migrations from On-Premises Approaches to Azure NetApp Files
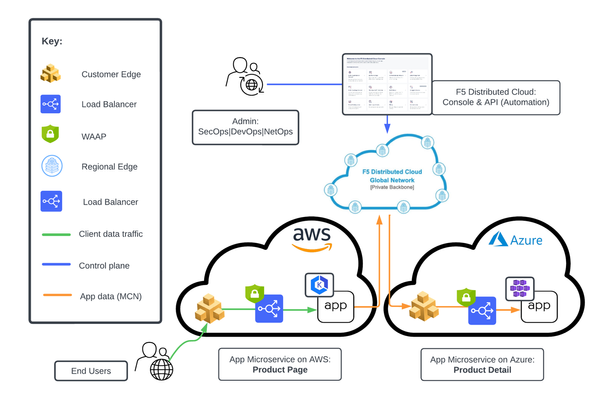
F5 Distributed Cloud (XC) Secure Multicloud Networking (MCN) connects and secures distributed applications across offices, data centers, and various cloud platforms. Frequently the technology is web-based, meaning traffic is often carried on ports like TCP port 443, however other traffic types are also prevalent in an enterprise’s traffic mix. Examples include SSH or relational database protocols. One major component of networked traffic is Network-Attached Storage (NAS), a protocol in the past frequently carried over LANs between employees in offices and co-located NAS appliances, perhaps in wiring closets or server rooms. An example of such an appliance would be the ONTAP family from NetApp which can take on physical or virtual form factors. NAS protocols are particularly useful as they integrate file stores into operating systems such as Microsoft Windows or Linux distributions as directories, mounted for easy access to files at any time, often permanently. This contrasts with SSH file transfers, which are often ephemeral actions and not so tightly integral to host operating system health. With the rise of remote work, often the NAS appliances see increasing file reads-and-writes to these directories, traversing wide-area links. In fact, one study analyzing fundamental traffic changes due to the Covid-19 pandemic saw a 22 percent increase in file transfer protocol (FTP) in a single year, suggesting access to files has undergone significant foundational changes in recent years. Distributed Cloud and the Movement towards Centralized Enterprise Storage A traditional concern about serving NAS files to offices from a centralized point, such as a cloud-instantiated file repository, is latency and reliability. With F5’s Distributed Cloud offering a 12 Tbps aggregate backbone and dedicated RE-to-RE links, the behavior of the network component is both highly durable and performant. The efficiencies of a centralized corporate file distribution point, with the required 9’s of guaranteed uptime of modern cloud services, and the logic of moving towards cloud-served NAS solutions makes a lot of sense. With on-premises storage appliances replaced by a secure, networked service eliminates the need to maintain costly spares, which are effectively a shadow NAS appliance infrastructure and onerous RMA procedures. All of this enables accomplishing the goal of shrinking/greening office wiring closets. To demonstrate this centralized model for a NAS architecture, a configuration was created whereby a west coast simulated office was connected by F5 Distributed Cloud to Azure NetApp Files (ANF) instantiated in Azure East-2 region. ANF is Microsoft Azure’s newest native file serving solution, managed by NetApp, with data throughputs that increase in lock step with the amount of reserved storage pool capacity. Different quality of service (QoS) levels are selectable by the consumer. In the streamlined ANF configuration workflow, where various transaction latency thresholds may be requested, even the most demanding relational database operations are typically accommodated. Microsoft offers additional details on ANF here, however, this article should serve to sufficiently demonstrate the ANF and F5 Distributed Cloud Secure MCN solutions for most readers. Distributed Cloud and Azure NetApp Files Deployment Example NAS in the enterprise today largely involves use of either NFS or SMB protocols, both of which can be used within Windows and Linux environments and make remote directories appear and perform as if local to users. In our example, a western US point of presence was leveraged to serve as the simulated remote office and standard Linux hosts to serve as the consumers of NetApp volumes. In the east, a corporate VNET was deployed in an Azure resource group (RG) in US-East-2, with one subnet delegated to provide Azure NetApp Files (ANF). To securely connect the west coast office to the eastern Azure ANF service, F5 Distributed Cloud Secure MCN was utilized to create a Layer 3 multi-cloud network offering. This is achieved by easily dropping an F5 customer edge (CE) virtual appliance into both the office and the Azure VNET in the east. The CE is a 2-port security appliance. The inside interfaces on both CEs were attached to a global virtual network, and exclusive layer-3 associations to allow simple connectivity and fully preserve privacy. In keeping with the promise of SaaS, Distributed Cloud users require no routing protocol setup. The solution takes care of the control plane, including routing and encryption. This concept could be scaled to hundreds of offices, if equipped with CEs, and easily attached to the same global virtual network. CEs, at boot-up, automatically attach via IP Sec (or SSL) tunnels to geographically close F5 backbone nodes, called regional edge (RE) sites. Like tunnel establishment, routing tables are updated under-the-hood to allow for a turn-key security relationship between Azure NetApp File volumes and consuming offices. The setup is depicted as follows: Setup Azure NetApp Files (ANF) Volumes in Minutes To put the centralized approach to offering NAS volumes for remote offices or locations into practice, a series of quick steps are undertaken, which can all be done through the standard Microsoft Azure portal. The four steps are listed below, with screenshots provided for key points in the brief process: If not starting from an existing Resource Group (RG), create a new RG and add an Azure VNET to it. Delegate one subnet in your VNET to support ANF. Under “Delegate Subnet to a Service” select from the pull-down-list the entry “Microsoft.NetApp/volumes”. Within the Resource Group, choose “Create” and make a NetApp account. This will appear in the Azure Marketplace listings as “Azure NetApp Files”. In your NetApp account, under “Storage service” create a capacity pool. The pool should be sized appropriately, larger is typically better, since numerous volumes, supporting your choice of NFS3/4 and SMB protocols, will be created from this single, large disk pool. Create your first volume, select size, NAS protocols to support, and QoS parameters that meet your business requirements. As seen below, when adding a capacity pool simply follow the numerical sequence to add your pool, with a newly created sample 2 TiB pool highlighted; 1,024 TiB (1 PiB) are possible (click image to enlarge). Interestingly, the capacity pool shown is the “Standard” service level, as opposed to “Premium” and “Ultra”. With QoS type of Auto selected, Azure NetApp Files provides increasing throughput in terms of megabytes per second as the number of TiB in the pool increases. The throughput also increases with service levels; for standard, as shown, 8 megabytes per second per TiB will be allocated. Beyond throughput, ANF also provides the lowest latency averages for reads and writes in the Azure portfolio of storage offerings. As such, ANF is a very good fit for database deployments that must see constrained, average latency for mission-critical transactions. Deeper discussion around ANF service levels may be explored through the Microsoft document here. The next screenshot shows the simple click-through sequence for adding a volume to the capacity pool, simply click on volumes and the “+Add volume” button. A resulting sample volume is displayed in the figure with key parameters highlighted. In the above volume (“f5-distributed-cloud-vol-001”) the NAS protocol selected was NFSv3 and the size of the volume (“Quota”) was set to 100GiB. Setup F5 Distributed Cloud Office-to-Azure Connectivity To access the volume in a secured and highly responsive manner, from corporate headquarters, remote offices or existing data centers, three items from F5 Distributed Cloud are required: A customer edge (CE) node, normally with 2-ports, must be deployed in the Azure RG VNET. This establishes the Azure instance as a “site” within the Distributed Cloud dashboard. Hub and spoke architectures may also be used if required, where VNET peering can also allow the secure multi-cloud network (MCN) solution to operate seamlessly. A CE is deployed at a remote office or datacenter, where file storage services are required by various lines of business. The CE is frequently deployed as a virtual appliance or installed on a bare metal server and typically has 2-ports. To instantiate a layer-3 MCN service, the inside ports of the two CEs are “joined” to a virtual global network created by the enterprise in the Distributed Cloud console, although REST API and Terraform are also deployment options. By having each inside port of the Azure and office CE’s joined to the same virtual network, the “inside” subnets can now communicate with each other, securely, with traffic normally exchanged over encrypted high-speed IPSec tunnels into the F5 XC global fabric. The following screenshot demonstrates adding the Azure CE inside interface to a global virtual network, allowing MCN connectivity to remote office clients requiring access to volumes. Further restrictions, to prevent unauthorized clients, are found within NAS protocols themselves, such as simple Export policies in NFS and ACL rules in SMB/CIFS, which can be configured quickly within ANF. Remote Office Access – Establish Read/Write File Access to Azure ANF over F5 Distributed Cloud With both ANF configured and F5 Distributed Cloud now providing a layer-3 muticloud network (MCN) solution, to patch enterprise offices to the centralized storage, some confirmation of the solution working as expected was desired. First off, a choice in protocols was made. When configuring ANF, the normal choices for access are NFSv3/v4 or SMB/CIFS or both protocols concurrently. Historically, Microsoft hosts made use of SMB/CIFS and Linux/Unix hosts preferred NFS, however today both protocols are used throughout enterprises. One example being long-time SAMBA server (SMB/CIFS) support in the world of Linux. Azure NetApp Files will provide all the necessary command samples to get hosts connected without difficulty. For instance, to mount the volume to a folder off the Linux user home directory, such as the sample folder “f5-distributed-cloud-vol-001”, per the ANF suggestion the following one command will connect the office Linux host to the central storage in Azure-East-2: sudo mount -t nfs -o rw,hard,rsize=262144,wsize=262144,vers=3,tcp 10.0.9.4:/f5-distributed-cloud-vol-001 f5-distributed-cloud-vol-001 At this point the volume is available for day-to-day tasks, including read and write operations, as if the NAS solution were local to the office, often literally down the hallway. Remote Office Access - Demonstration of Azure ANF over F5 Distributed Cloud i zThe following sample wrote a file of 20,000 bytes to the ANF service, waited a few seconds, and then removed the file before beginning another cycle. At the lowest common denominator, packet analysis for the ensuing traffic from the western US office will indicate both network and application latency sample values. As depicted in the following Wireshark trace, the TCP response to a transmitted segment carrying an NFS command, was observed to be just 74.5 milliseconds. This prompt round-trip latency for a cross-continent data plane suggests a performant Distributed Cloud MCN service level. This is easily seen as the offset from the reference timestamp (time equal to zero) of the NFS v3 Create Call. Click on image to expand. Analyzing the NAS response from ANF (packet 185) arrives less than 1 millisecond later, suggesting a very responsive, well-tuned NFS control plane offered by ANF. To measure the actual, write-time of a file from west coast to east coast, the following trace demonstrates the 20,000 byte file write exercise from the shell script. In this case, the TCP segments making up the file, specifically the large packet body lengths called out in the screenshot, are delivered efficiently without TCP retransmissions, TCP zero window events, nor having any indicators of layer 3 and 4 health concerns. The entirety of the write is measured at the packet layer to take only 150.8 milliseconds. Since packet-level analysis is not the most turnkey, easy method to monitor file read and write performance, a set of Linux and Windows utilities can also be leveraged. The Linux utility nfsiostat was concurrently used with the test file writes and produced similar, good latency measurements. Nfsiostat monitoring of the file write testing, from west coast to east coast, for the 20,000-byte file, has indicated an average write time to ANF of 151 milliseconds. The measurements presented here are simply observational, to present rapid, digestible techniques for readers interested in service assurance for running ANF over an XC L3 MCN offering. For more rigorous monitoring treatments, Microsoft provides guidance on performing one’s own measurements of Azure NetApp Files here. Summary As enterprise-class customers continue to rapidly look towards cloud for compute performance, GPU access, and economies-of-scale savings for key workloads, the benefits of a centralized, scalable storage counterpart to this story exists. F5 Distributed Cloud offers the reach and performance levels to securely tie existing offices and data centers to cloud-native storage solutions. One example of this approach to modernize storage was covered in this article, the turn-key ability to begin transitioning from traditionally on-premises NAS appliances to cloud-native scalable volumes. The Azure NetApp Files approach to serving read/write volumes allows modern hosts, including Windows and Linux distributions, to utilize virtually unlimited folder sizes with service levels adjustable to business needs.86Views0likes1CommentThe App Delivery Fabric with Secure Multicloud Networking
This tutorial with accompanying workflow guide deploys customer edge sites and uses Distributed Cloud Multicloud Networking App Connect to establish a Secure MCN App Delivery Fabric, enabling only Layer7 app connectivity between two cloud sites. Manual and automation workflows show how to make this NetOps and DevOps task come to life.169Views1like0CommentsHow To Run Ollama On F5 AppStack With An NVIDIA GPU In AWS
If you're just getting started with AI, you'll want to watch this one, as Michael Coleman shows Aubrey King, from DevCentral, how to run Ollama on F5 AppStack on an AWS instance with an NVIDIA Tesla T4 GPU. You'll get to see the install, what it looks like when a WAF finds a suspicious conversation and even a quick peek at how Mistral handles a challenge differently than Gemma. 103Views2likes0Comments
103Views2likes0CommentsIntroducing Secure MCN features on F5 Distributed Cloud
Introduction F5 Distributed Cloud Services offers many secure multi-cloud networking features. In the video linked below, I demonstrate how to connect a Secure Mesh Customer Edge (CE) Site running on VMware and using common hardware. This on-prem CE is joined to a site mesh group of three other CE's, two of which are run on the public cloud providers AWS and Azure. Secure Mesh CE is a newly enhanced feature in Distributed Cloud that allows CE's not running in public cloud providers to run on hardware with unique and different configurations. Specifically, it's now possible to deploy site mesh transit networking to all CE's having one, two, or more NIC's, with each CE having its own unique physical configuration for networking. See my article on Secure Mesh Site Networking to learn how to set up and configure secure mesh sites. In addition to secure mesh networking, on-prem CE's can be deployed without app management features, giving organizations the flexibility to conserve deployed resources. Organizations can now choose whether to deploy AppStack CE's, where the CE's can manage and run K8s compute workloads deployed at the site, or use networking-focused CE's freeing up resources that would otherwise be used managing the apps. Whether deploying an AppStack or Secure Mesh CE, both types support Distributed Cloud's comprehensive set of security features, including DDoS, WAF, API protection, Bot, and Risk management. Secure MCN deployment capabilities include the following capabilities: Secure Multi-Cloud Network Fabric (secure connectivity) Discover any app running anywhere across your environments Cloud/On-Prem Customer Edge (CE) Private link connectivity orchestration with F5 XC as-a-service using any transport provider ➡️ Example: AWS PrivateLink, Azure CloudLink, Private transport (IP, MPLS, etc) L3 Network Connect & L7 App Connect capabilities L3/L4 DDoS + Enhanced intent-based firewall policies Security Service insertion w/ support for BIG-IP and Palo Alto Firewalls Application Security Services - WAF, API Protection, L7 DoS, Bot Defense, Client-side defense and more SaaS and Automation for Security, Network, & Edge Compute Powerful monitoring dashboards & troubleshooting tools for the entire secure multi-cloud network fabric Gain visibility into how and which API's are being consumed in workflows ➡️ Monitor and troubleshoot apps including their API's In the following video, I introduce the components that make up a Secure MCN deployment, and then walk through configuring the security features and show how to observe app performance and remediate security related incidents. 0-3:32 - Overview of Secure MCN features 3:32-9:20 - Product Demo Resources Distributed Cloud App Delivery Fabric Workflow Guide (GitHub) Secure MCN Article Series Secure MCN Intro: Introducing Secure MCN features on F5 Distributed Cloud Secure MCN Part 1: Using Distributed Application Security Policies in Secure Multicloud Networking Customer Edge Sites Secure MCN Part 2: The App Delivery Fabric with Secure Multicloud Networking Secure MCN Part 3: Coming Soon: The Secure Network Fabric with Multicloud Network Segmentation & Private Provider Network Connectivity Related Technical Articles 🔥 ➡️ Combining the key aspects of Secure MCN with GenAI apps: Protect multi-cloud and Edge Generative AI applications with F5 Distributed Cloud Secure Mesh Site Networking (DevCentral) A Complete Multi-Cloud Networking Walkthrough (DevCentral) Product Documentation How-To Create Secure Mesh Sites Product Information Distributed Cloud Network Connect Distributed Cloud App Connect1.6KViews1like0CommentsDeploying F5 Distributed Cloud (XC) Services in Cisco ACI - Layer Two Attached Deployment
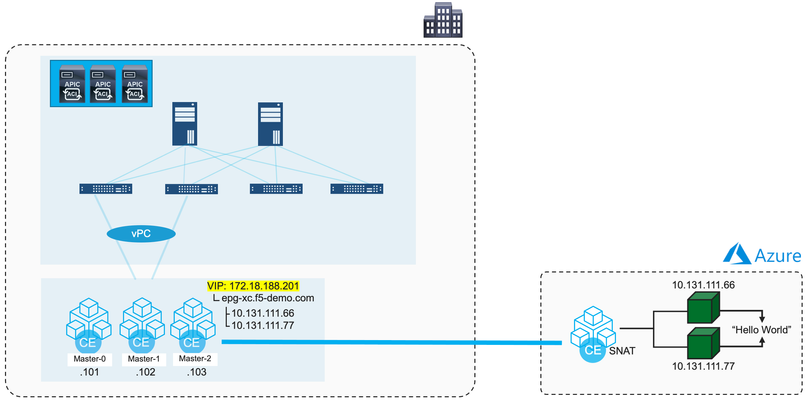
Introduction F5 Distributed Cloud (XC) Services are SaaS-based security, networking, and application management services that can be deployed across multi-cloud, on-premises, and edge locations. This article will show you how you can deploy F5 Distributed Cloud’s Customer Edge (CE) site in Cisco Application Centric Infrastructure (ACI) so that you can securely connect your application and distribute the application workloads in a Hybrid Multi-Cloud environment. F5 XC Layer Two Attached CE in Cisco ACI Besides Layer Three Attached deployment option, which we discussed in another article, a F5 Distributed Cloud Customer Edge (CE) site can also be deployed with Layer Two Attached in Cisco ACI environment using an ACI Endpoint of an Endpoint Group (EPG). As a reminder, Layer Two Attached is one of the deployment models to get traffic to/from a F5 Distributed Cloud CE site, where the CE can be a single node or a three-nodes cluster. F5 Distributed Cloud supports Virtual Router Redundancy Protocol (VRRP) for virtual IP (VIP) advertisement. When VRRP is enabled for VIPs advertisement, there is a VRRP Master for each of the VIPs and the VRRP Master for each of the VIPs can possibly be distributed across the CE nodes within the cluster. In this article, we will look at how we can deploy a Layer Two Attached CE site in Cisco ACI. F5 XC VRRP Support for VIPs Advertisement F5 XC Secure Mesh Sites are specifically engineered for non-cloud CE deployments, which support additional configurations that are not available using Fleet or regular Site management functionalities such as VRRP for VIPs advertisement. We recommend Secure Mesh Sites for non-cloud CE deployment and specifically, in Layer Two Attached CE deployment model, we recommend deploying CE site as a Secure Mesh Site to take advantage of the VRRPs support for VIPs advertisement. With VRRP enabled for VIPs advertisement, one of the CE nodes within the cluster will become the VRRP Master for a VIP and starts sending gratuitous ARPs (GARPS) while the rest of the CE nodes will become the VRRP Backup. Please note that in CE software, VRRP virtual MAC is not used for the VIP. Instead, the CE node, which is the VRRP Master for the VIP uses its physical MAC address in ARP responses for the VIP. When a failover happens, a VRRP Backup CE will become the new VRRP Master for the VIP and starts sending GARPs to update the ARP table of the devices in the broadcast domain. As of today, there isn't a way to configure the VRRP priority and the VRRP Master assignment is at random. Thus, if there are multiple VIPs, it is possible that a CE node within the cluster can be the VRRP Master for one or more VIPs, or none. F5 XC Layer Two Attached CE in ACI Example In this section, we will use an example to show you how to successfully deploy a Layer Two Attached CE site in Cisco ACI fabric so that you can securely connect your application and distribute the application workloads in a Hybrid Multi-Cloud environment. Topology In our example, CE is a three nodes cluster (Master-0, Master-1 and Master-2) which connects to the ACI fabric using an endpoint of an EPG namedexternal-epg: Example reference - ACI EPG external-epg endpoints table: HTTP load balancersite2-secure-mesh-cluster-app has a Custom VIP of 172.18.188.201/32 epg-xc.f5-demo.com with workloads 10.131.111.66 and 10.131.111.77 in the cloud (Azure) and it advertises the VIP to the CE site: F5 XC Configuration of VRRP for VIPs Advertisement To enable VRRP for VIPs advertisement, go to "Multi-Cloud Network Connect" -> "Manage" -> "Site Management" -> "Secure Mesh Sites" -> "Manage Configuration" from the selected Secure Mesh Site: Next, go to "Network Configuration" and select "Custom Network Configuration" to get to "Advanced Configuration" and make sure "Enable VRRP for VIP(s)" is selected for VIP Advertisement Mode: Validation We can now securely connect to our application: Note from above, after F5 XC is deployed in Cisco ACI, we also use F5 XC DNS as our primary nameserver: To check the requests on the F5 XC Console, go to"Multi-Cloud App Connect" -> "Overview: Applications" to bring out our HTTP load balancer, then go to "Performance Monitoring" -> "Requests": *Note: Make sure you are in the right namespace. As a reminder, VRRP for VIPs advertisement is enabled in our example. From the request shown above, we can see that CE node Master-2 is currently the VRRP Master for VIP 172.18.188.201 and if we go to the APIC, we can see the VIP is learned in the ACI endpoint table for EPG external-epgtoo: Example reference - a sniffer capture of GARP from CE node Master-2 for VIP 172.18.188.201: Summary A F5 Distributed Cloud Customer Edge (CE) site can be deployed with Layer Two Attached deployment model in Cisco ACI environment using an ACI Endpoint of an Endpoint Group (EPG). Layer Two Attached deployment model can be more desirable and easier for CE deployment when compared to Layer Three Attached. It is because Layer Two Attached does not require layer three/routing which means one less layer to take care of and it also brings the applications closer to the edge. With F5 Distributed Cloud Customer Edge (CE) site deployment, you can securely connect your on-premises to the cloud quickly and efficiently. Next Check out this video for some examples of Layer Two Attached CE use cases in Cisco ACI: Related Resources *On-Demand Webinar* Deploying F5 Distributed Cloud Services in Cisco ACI Deploying F5 Distributed Cloud (XC) Services in Cisco ACI - Layer Three Attached Deployment Customer Edge Site - Deployment & Routing Options Cisco ACI Endpoint Learning White Paper325Views0likes0CommentsDeploying F5 Distributed Cloud (XC) Services in Cisco ACI - Layer Three Attached Deployment
Introduction F5 Distributed Cloud (XC) Services are SaaS-based security, networking, and application management services that can be deployed across multi-cloud, on-premises, and edge locations. This article will show you how you can deploy F5 Distributed Cloud Customer Edge (CE) site in Cisco Application Centric Infrastructure (ACI) so that you can securely connect your application in Hybrid Multi-Cloud environment. XC Layer Three Attached CE in Cisco ACI A F5 Distributed Cloud Customer Edge (CE) site can be deployed with Layer Three Attached in Cisco ACI environment using Cisco ACI L3Out. As a reminder, Layer Three Attached is one of the deployment models to get traffic to/from a F5 Distributed Cloud CE site, where the CE can be a single node or a three nodes cluster. Static routing and BGP are both supported in the Layer Three Attached deployment model. When a Layer Three Attached CE site is deployed in Cisco ACI environment using Cisco ACI L3Out, routes can be exchanged between them via static routing or BGP. In this article, we will focus on BGP peering between Layer Three Attached CE site and Cisco ACI Fabric. XC BGP Configuration BGP configuration on XC is simple and it only takes a couple steps to complete: 1) Go to "Multi-Cloud Network Connect" -> "Networking" -> "BGPs". *Note: XC homepage is role based, and to be able to configure BGP, "Advanced User" is required. 2) "Add BGP" to fill out the site specific info, such as which CE Site to run BGP, its BGP AS number etc., and "Add Peers" to include its BGP peers’ info. *Note: XC supports direct connection for BGP peering IP reachability only. XC Layer Three Attached CE in ACI Example In this section, we will use an example to show you how to successfully bring up BGP peering between a F5 XC Layer Three Attached CE site and a Cisco ACI Fabric so that you can securely connect your application in Hybrid Multi-Cloud environment. Topology In our example, CE is a three nodes cluster(Master-0, Master-1 and Master-2) that has a VIP 10.10.122.122/32 with workloads, 10.131.111.66 and 10.131.111.77, in the cloud (AWS): The CE connects to the ACI Fabricvia a virtual port channel (vPC) that spans across two ACI boarder leaf switches. CE and ACI Fabric are eBGP peers via an ACI L3Out SVI for routes exchange. CE is eBGP peered to both ACI boarder leaf switches, so that in case one of them is down (expectedly or unexpectedly), CE can still continue to exchange routes with the ACI boarder leaf switch that remains up and VIP reachability will not be affected. XC BGP Configuration First, let us look at the XC BGP configuration ("Multi-Cloud Network Connect" -> "Networking" -> "BGPs"): We"Add BGP" of "jy-site2-cluster" with site specific BGP info along with a total of six eBGP peers (each CE node has two eBGP peers; one to each ACI boarder leaf switch): We "Add Item" to specify each of the six eBPG peers’ info: Example reference - ACI BGP configuration: XC BGP Peering Status There are a couple of ways to check the BGP peering status on the F5 Distributed Cloud Console: Option 1 Go to "Multi-Cloud Network Connect" -> "Networking" -> "BGPs" -> "Show Status" from the selected CE site to bring up the "Status Objects" page. The "Status Objects" page provides a summary of the BGP status from each of the CE nodes. In our example, all three CE nodes from "jy-site2-cluster" are cleared with "0 Failed Conditions" (Green): We can simply click on a CE node UID to further look into the BGP status from the selected CE node with all of its BGP peers. Here, we clicked on the UID of CE node Master-2 (172.18.128.14) and we can see it has two eBGP peers: 172.18.128.11 (ACI boarder leaf switch 1) and 172.18.128.12 (ACI boarder leaf switch 2), and both of them are Up: Here is the BGP status from the other two CE nodes - Master-0 (172.18.128.6) and Master-1 (172.18.128.10): For reference, here is an example of a CE node with "Failed Conditions" (Red) due to one of its BGP peers is down: Option 2 Go to "Multi-Cloud Network Connect" -> "Overview" -> "Sites" -> "Tools" -> "Show BGP peers" to bring up the BGP peers status info from all CE nodes from the selected site. Here, we can see the same BGP status of CE node master-2 (172.18.128.14) which has two eBGP peers: 172.18.128.11 (ACI boarder leaf switch 1) and 172.18.128.12 (ACI boarder leaf switch 2), and both of them are Up: Here is the output of the other two CE nodes - Master-0 (172.18.128.6) and Master-1 (172.18.128.10): Example reference - ACI BGP peering status: XC BGP Routes Status To check the BGP routes, both received and advertised routes, go to "Multi-Cloud Network Connect" -> "Overview" -> "Sites" -> "Tools" -> "Show BGP routes" from the selected CE sites: In our example, we see all three CE nodes (Master-0, Master-1 and Master-2) advertised (exported) 10.10.122.122/32 to both of its BPG peers: 172.18.128.11 (ACI boarder leaf switch 1) and 172.18.128.12 (ACI boarder leaf switch 2), while received (imported) 172.18.188.0/24 from them: Now, if we check the ACI Fabric, we should see both 172.18.128.11 (ACI boarder leaf switch 1) and 172.18.128.12 (ACI boarder leaf switch 2) advertised 172.18.188.0/24 to all three CE nodes, while received 10.10.122.122/32 from all three of them (note "|" for multipath in the output): XC Routes Status To view the routing table of a CE node (or all CE nodes at once), we can simply select "Show routes": Based on the BGP routing table in our example (shown earlier), we should see each CE node has two Equal Cost Multi-Path (ECMP) installed in the routing table for 172.18.188.0/24: one to 172.18.128.11 (ACI boarder leaf switch 1) and one to 172.18.128.12 (ACI boarder leaf switch 2) as the next-hop, and we do (note "ECMP" for multipath in the output): Now, if we check the ACI Fabric, each of the ACI boarder leaf switch should have three ECMP installed in the routing table for 10.10.122.122: one to each CE node (172.18.128.6, 172.18.128.10 and 172.18.128.14) as the next-hop, and we do: Validation We can now securely connect our application in Hybrid Multi-Cloud environment: *Note: After F5 XC is deployed, we also use F5 XC DNS as our primary nameserver: To check the requests on the F5 Distributed Cloud Console, go to"Multi-Cloud Network Connect" -> "Sites" -> "Requests" from the selected CE site: Summary A F5 Distributed Cloud Customer Edge (CE) site can be deployed with Layer Three Attached deployment model in Cisco ACI environment. Both static routing and BGP are supported in the Layer Three Attached deployment model and can be easily configured on F5 Distributed Cloud Console with just a few clicks. With F5 Distributed Cloud Customer Edge (CE) site deployment, you can securely connect your application in Hybrid Multi-Cloud environment quickly and efficiently. Next Check out this video for some examples of Layer Three Attached CE use cases in Cisco ACI: Related Resources *On-Demand Webinar*Deploying F5 Distributed Cloud Services in Cisco ACI Deploying F5 Distributed Cloud (XC) Services in Cisco ACI - Layer Two Attached Deployment Customer Edge Site - Deployment & Routing Options Cisco ACI L3Out White Paper1.2KViews4likes0CommentsTaming your “Chaos Monkey” with F5 Distributed Cloud Platform
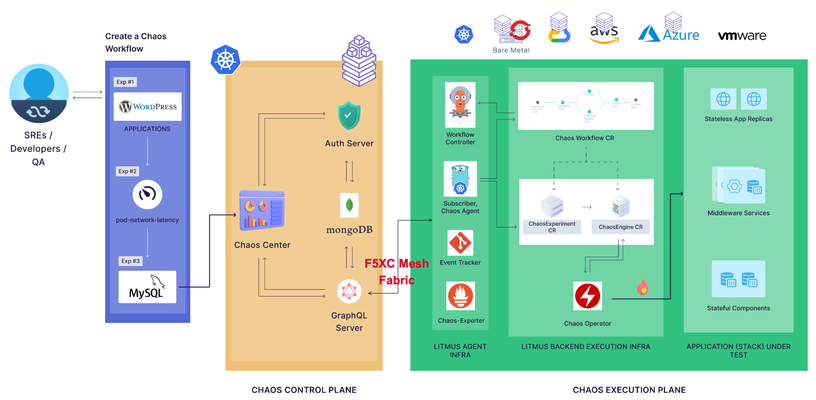
Overview Recently, my family returned from a holiday trip to Japan. While the holiday itself was amazing, this article isn't about the experiences or the chaos my children caused; rather, it's about the significant role technology and applications played in enhancing our vacation and our lives in the digital world. Please also notes that “Application” in this context loosely use to refer to software/applications/AI apps/API or systems that power the digital world. Throughout our journey, we found ourselves heavily reliant on various applications, ranging from weather forecasts to navigation aids. We utilized weather apps to stay informed and dressed appropriately, GPS apps to navigate bustling cities and public transportation, and mobile payment apps for seamless transactions. Social media platforms allowed us to update family and friends on our whereabouts, while continuous access to mobile internet (via 4/5G connectivity) kept us tethered to the digital world. Additionally, we interacted with numerous indirect applications and systems, such as ordering food in cafes, different ticketing systems, or using Automated Teller Machines (ATM) for cash withdrawals. Reflecting on these travel experiences prompts consideration of the potential implications had these apps not existed or malfunctioned during our visit. While it might not have been catastrophic, it would have certainly detracted from the smoothness and enjoyment of our holiday. For instance, the failure of my mobile payment app could have hindered transactions, or what if a life-threatening event occurred and the network went down, accessing emergency services would have been impossible—a potentially catastrophic situation that I couldn’t had imagine. The crux of the matter is the paramount importance of ensuring that these applications remain always available, secure, and resilient. They have become integral to modern life, not just enhancing convenience but also playing a crucial role in safety and well-being. Therefore, efforts to maintain their reliability and functionality are imperative in navigating our increasingly digital world. In our increasingly interconnected world, reliance on technology already ubiquitous. The resilience of apps and systems is now a paramount concern for any organization, occupying the top priority in the minds of many executives (CxOs). When these systems fail, causing disruptions for customers or citizens, CxOs may find themselves compelled to respond publicly or even testify before various authorities, demonstrating their due diligence in managing and maintaining these critical assets. Hence, organization need to have strategies to assess and analyse failure mode and impact analysis of those critical application failure. Numerous methodical strategies exist to study and ensure the resilience of apps and systems, such as Failure Modes, Effects, and Criticality Analysis (FMECA), Failure Mode and Effects Analysis (FMEA), and Chaos Engineering. While the intricacies of these methodologies won't be covered in depth here, it's important to introduce them and highlight their shared objective: mitigating business/availability risks to prevent harm to business when apps or systems encounter failures. The focus of this article is to demonstrate how F5's Distributed Cloud (F5XC) Secure Multi-Cloud Networking (MCN) for Kubernetes can address some of these failure scenarios, particularly through the lens of Chaos Engineering. Chaos Engineering involves deliberately inducing failures in a controlled environment to test system resilience. In this demonstration, I’ll leverage the Open Source Chaos Engineering platform to simulate failure scenarios within a running production system. I will use a sample financial application, Arcadia Finance, as our subject for chaos testing. This application consists of microservices distributed across heterogeneous Kubernetes environments, including Amazon EKS, Azure AKS, Google GKE, and Red Hat OpenShift Container Platform (OCP). F5's XC Mesh for Kubernetes can run on any of these Kubernetes platforms and itself formed a secure mesh fabric to orchestrate apps connectivity, delivery, security and observability between those heterogenous container platform. Regardless of the specific strategy employed, the goal remains consistent: implementing risk prevention strategies to safeguard against the potential harm to business caused by app or system failures. Please do note that full end-to-end demo video at the end of this article. Below are some of the mentioned methodologies. Please refer to respective literature for details. FMECA / FMEA From “Find failure and fix it” to “anticipate failure and prevent it” Extracted from (https://www.getmaintainx.com/learning-center/what-is-fmeca-failure-mode-effects-and-critical-analysis/) FMECA is a risk assessment methodology in which you determine failure modes, assess their level of risk to your equipment or system, and rate the failure based on that level of risk. The U.S. military invented this FMECA analysis technique in the ‘40s. The military continues to use the FMECA even today under the MIL STD-1629A. FMECA is a commonly used technique for performing failure detection and criticality analysis on systems to improve their performance. In addition, it typically provides input for Maintainability Analysis and Logistics Support Analysis, both of which rely on FMECA data. With Industry 4.0, many industries are adopting a predictive maintenance strategy for their equipment. To prioritize failure modes and identify mechanical system and subsystem issues for predictive maintenance, FMECA is a widely used tool. Chaos Engineering Excerpt from https://www.gremlin.com/community/tutorials/chaos-engineering-the-history-principles-and-practice Chaos Engineering is a disciplined approach to identifying failures before they become outages. By proactively testing how a system responds under stress, you can identify and fix failures before they end up in the news. Chaos Engineering lets you compare what you think will happen to what actually happens in your systems. You literally “break things on purpose” to learn how to build more resilient systems Note: Chaos Monkey serves as a critical tool in enhancing chaos engineering; it enables engineering teams to simulate failures across multiple configurations and monitor the system's behaviour in real time. It was a set of tools that originally open source by Netflix. In this demo, Open Source Litmus will be use instead of Chaos Monkey. Litmus Chaos Platform Litmus is an open source Chaos Engineering platform that enables teams to identify weaknesses & potential outages in infrastructures by inducing chaos tests in a controlled way. It is a Cloud-Native Chaos Engineering Framework with cross-cloud support. It is a CNCF Incubating project with adoption across several organizations. Its mission is to help Kubernetes SREs and Developers to find weaknesses in both Non-Kubernetes as well as platforms and applications running on Kubernetes by providing a complete Chaos Engineering framework and associated Chaos Experiments. Litmus adopts a "Kubernetes-native" approach to define chaos intent in a declarative manner via Kubernetes custom resources (CRs). Litmus platform consist of Control Plane, Execution Plane and Chaos Fault flow. Please refer to official documentation for details - https://docs.litmuschaos.io/docs/introduction/what-is-litmus Chaos Center (Chaos Control Plane) is deployed on F5XC AppStack and Chaos Execution Plane (Litmus Agents/Infrastructure) installed on respective Kubernetes Platform. Litmus agents communicate with Chaos Center via F5XC Secure Mesh Fabric. This is a Traffic Graph where Litmus agent on respective K8S communicating to Chaos Centre over websocket connection. These private connections are secured and protected by F5XC. Chaos Engineering Demo - High Level Demo Architecture In this demo environment, Litmus agents are deployed on both Amazon EKS and Red Hat OCP. Arcadia Finance, comprising multiple microservices (applications and APIs), are distributed across heterogeneous container platforms. The demo will focus on two specific use cases: Use Case #1: Frontend Application Latency Demonstrating network latency impacting frontend applications (EKS), resulting in unresponsive app behavior within critical timeframes. Use Case #2: Production Deployment Issues Showcasing the deployment of an updated version of the money-transfer API container (OCP) leading to the money-transfer API pods entering a CrashLoopBack state, hindering production functionality. Litmus (open source) is capable to inject more than 50 chaos experiment – for example, on Kubernetes; pods kill, pod delete, network latency, pod network disruption, node failure and many more. Please refer to litmus documentation for the complete list of chaos. F5 Distributed Cloud Platform Customer Edge Sites Arcadia Finance Sample Application Construct Litmus Chaos Environment for this Demo Litmus agents installed, registered and connected onto Litmus Chaos Center via F5XC Mesh Fabric. Litmus Chaos Center installed on F5's AppStack Kubernetes. Chaos Experiment created for arcadia frontend 4s network latency injected into arcadia frontend Continuous probe (health check) of the frontend to ensure application still functioning and accessible Without multi-cluster resiliency Injected chaos network latency Running Chaos Experiment workflow Logs shown on F5XC before adding multi cluster resiliency. As shown after 4s latency injected to frontend (served from foobz-mesh-eks1), user/probe unable to get to frontend and subsequent request return 503 error as no available site to handle the introduce network latency. End user will received 503 error – “application down” Chaos Experiments test completed with Failure and Resilience Score to 0%. End Result - Application unavailable. Resilient Score - 0% With multi-cluster resiliency Introduce Google Cloud GKE as part of the backup origin pool for arcadia frontend via CI/CD Pipeline. In the even if frontend on EKS unable to handle or failed, traffic will be steered/redirected to GKE. Similar Chaos experience will be run and completed successful with Resilience Score of 100%. From XC request logs shown traffic seamlessly transition from "foobz-mesh-eks1" to "foobz-mesh-gke1" End Result - Application Always Available. Resilient Score - 100% Similar backup site ("foobz-mesh-aks1") will be added via CI/CD Pipeline into the money-transfer apps/api to provide high redundancy. Deployment of rogue software onto money-transfer api pods that causes money-transfer pod into a CrashLoopBack. From XC logs, you can see that money-transfer served from foobz-ves-ocp-sg transition to foobz-mesh-aks1 seamlessly While refer-friend module still remain in foobz-ves-ocp-sg as refer-friend apps/api are healthy in foobz-ves-ocp-sg End-Result with F5 Distributed Cloud Mesh Demo Video Summary F5 is delivering on its mission to make it significantly easier to secure, deliver, and optimize any app, any API, anywhere. We strive to bring a better digital world to life. Our teams empower organization across the globe to create, secure, and run applications that enhance how we experience our evolving digital world.191Views1like2CommentsProtect multi-cloud and Edge Generative AI applications with F5 Distributed Cloud
F5 Distributed Cloud capabilities allows customers to use a single platform for connectivity, application delivery and security of GenAI applications in any cloud location and at the Edge, with a consistent and simplified operational model, a game changer for streamlined operational experience for DevOps, NetOps and SecOps.395Views3likes0Comments