5 Years Later: OpenAJAX Who?
Five years ago the OpenAjax Alliance was founded with the intention of providing interoperability between what was quickly becoming a morass of AJAX-based libraries and APIs. Where is it today, and why has it failed to achieve more prominence? I stumbled recently over a nearly five year old article I wrote in 2006 for Network Computing on the OpenAjax initiative. Remember, AJAX and Web 2.0 were just coming of age then, and mentions of Web 2.0 or AJAX were much like that of “cloud” today. You couldn’t turn around without hearing someone promoting their solution by associating with Web 2.0 or AJAX. After reading the opening paragraph I remembered clearly writing the article and being skeptical, even then, of what impact such an alliance would have on the industry. Being a developer by trade I’m well aware of how impactful “standards” and “specifications” really are in the real world, but the problem – interoperability across a growing field of JavaScript libraries – seemed at the time real and imminent, so there was a need for someone to address it before it completely got out of hand. With the OpenAjax Alliance comes the possibility for a unified language, as well as a set of APIs, on which developers could easily implement dynamic Web applications. A unified toolkit would offer consistency in a market that has myriad Ajax-based technologies in play, providing the enterprise with a broader pool of developers able to offer long term support for applications and a stable base on which to build applications. As is the case with many fledgling technologies, one toolkit will become the standard—whether through a standards body or by de facto adoption—and Dojo is one of the favored entrants in the race to become that standard. -- AJAX-based Dojo Toolkit , Network Computing, Oct 2006 The goal was simple: interoperability. The way in which the alliance went about achieving that goal, however, may have something to do with its lackluster performance lo these past five years and its descent into obscurity. 5 YEAR ACCOMPLISHMENTS of the OPENAJAX ALLIANCE The OpenAjax Alliance members have not been idle. They have published several very complete and well-defined specifications including one “industry standard”: OpenAjax Metadata. OpenAjax Hub The OpenAjax Hub is a set of standard JavaScript functionality defined by the OpenAjax Alliance that addresses key interoperability and security issues that arise when multiple Ajax libraries and/or components are used within the same web page. (OpenAjax Hub 2.0 Specification) OpenAjax Metadata OpenAjax Metadata represents a set of industry-standard metadata defined by the OpenAjax Alliance that enhances interoperability across Ajax toolkits and Ajax products (OpenAjax Metadata 1.0 Specification) OpenAjax Metadata defines Ajax industry standards for an XML format that describes the JavaScript APIs and widgets found within Ajax toolkits. (OpenAjax Alliance Recent News) It is interesting to see the calling out of XML as the format of choice on the OpenAjax Metadata (OAM) specification given the recent rise to ascendancy of JSON as the preferred format for developers for APIs. Granted, when the alliance was formed XML was all the rage and it was believed it would be the dominant format for quite some time given the popularity of similar technological models such as SOA, but still – the reliance on XML while the plurality of developers race to JSON may provide some insight on why OpenAjax has received very little notice since its inception. Ignoring the XML factor (which undoubtedly is a fairly impactful one) there is still the matter of how the alliance chose to address run-time interoperability with OpenAjax Hub (OAH) – a hub. A publish-subscribe hub, to be more precise, in which OAH mediates for various toolkits on the same page. Don summed it up nicely during a discussion on the topic: it’s page-level integration. This is a very different approach to the problem than it first appeared the alliance would take. The article on the alliance and its intended purpose five years ago clearly indicate where I thought this was going – and where it should go: an industry standard model and/or set of APIs to which other toolkit developers would design and write such that the interface (the method calls) would be unified across all toolkits while the implementation would remain whatever the toolkit designers desired. I was clearly under the influence of SOA and its decouple everything premise. Come to think of it, I still am, because interoperability assumes such a model – always has, likely always will. Even in the network, at the IP layer, we have standardized interfaces with vendor implementation being decoupled and completely different at the code base. An Ethernet header is always in a specified format, and it is that standardized interface that makes the Net go over, under, around and through the various routers and switches and components that make up the Internets with alacrity. Routing problems today are caused by human error in configuration or failure – never incompatibility in form or function. Neither specification has really taken that direction. OAM – as previously noted – standardizes on XML and is primarily used to describe APIs and components - it isn’t an API or model itself. The Alliance wiki describes the specification: “The primary target consumers of OpenAjax Metadata 1.0 are software products, particularly Web page developer tools targeting Ajax developers.” Very few software products have implemented support for OAM. IBM, a key player in the Alliance, leverages the OpenAjax Hub for secure mashup development and also implements OAM in several of its products, including Rational Application Developer (RAD) and IBM Mashup Center. Eclipse also includes support for OAM, as does Adobe Dreamweaver CS4. The IDE working group has developed an open source set of tools based on OAM, but what appears to be missing is adoption of OAM by producers of favored toolkits such as jQuery, Prototype and MooTools. Doing so would certainly make development of AJAX-based applications within development environments much simpler and more consistent, but it does not appear to gaining widespread support or mindshare despite IBM’s efforts. The focus of the OpenAjax interoperability efforts appears to be on a hub / integration method of interoperability, one that is certainly not in line with reality. While certainly developers may at times combine JavaScript libraries to build the rich, interactive interfaces demanded by consumers of a Web 2.0 application, this is the exception and not the rule and the pub/sub basis of OpenAjax which implements a secondary event-driven framework seems overkill. Conflicts between libraries, performance issues with load-times dragged down by the inclusion of multiple files and simplicity tend to drive developers to a single library when possible (which is most of the time). It appears, simply, that the OpenAJAX Alliance – driven perhaps by active members for whom solutions providing integration and hub-based interoperability is typical (IBM, BEA (now Oracle), Microsoft and other enterprise heavyweights – has chosen a target in another field; one on which developers today are just not playing. It appears OpenAjax tried to bring an enterprise application integration (EAI) solution to a problem that didn’t – and likely won’t ever – exist. So it’s no surprise to discover that references to and activity from OpenAjax are nearly zero since 2009. Given the statistics showing the rise of JQuery – both as a percentage of site usage and developer usage – to the top of the JavaScript library heap, it appears that at least the prediction that “one toolkit will become the standard—whether through a standards body or by de facto adoption” was accurate. Of course, since that’s always the way it works in technology, it was kind of a sure bet, wasn’t it? WHY INFRASTRUCTURE SERVICE PROVIDERS and VENDORS CARE ABOUT DEVELOPER STANDARDS You might notice in the list of members of the OpenAJAX alliance several infrastructure vendors. Folks who produce application delivery controllers, switches and routers and security-focused solutions. This is not uncommon nor should it seem odd to the casual observer. All data flows, ultimately, through the network and thus, every component that might need to act in some way upon that data needs to be aware of and knowledgeable regarding the methods used by developers to perform such data exchanges. In the age of hyper-scalability and über security, it behooves infrastructure vendors – and increasingly cloud computing providers that offer infrastructure services – to be very aware of the methods and toolkits being used by developers to build applications. Applying security policies to JSON-encoded data, for example, requires very different techniques and skills than would be the case for XML-formatted data. AJAX-based applications, a.k.a. Web 2.0, requires different scalability patterns to achieve maximum performance and utilization of resources than is the case for traditional form-based, HTML applications. The type of content as well as the usage patterns for applications can dramatically impact the application delivery policies necessary to achieve operational and business objectives for that application. As developers standardize through selection and implementation of toolkits, vendors and providers can then begin to focus solutions specifically for those choices. Templates and policies geared toward optimizing and accelerating JQuery, for example, is possible and probable. Being able to provide pre-developed and tested security profiles specifically for JQuery, for example, reduces the time to deploy such applications in a production environment by eliminating the test and tweak cycle that occurs when applications are tossed over the wall to operations by developers. For example, the jQuery.ajax() documentation states: By default, Ajax requests are sent using the GET HTTP method. If the POST method is required, the method can be specified by setting a value for the type option. This option affects how the contents of the data option are sent to the server. POST data will always be transmitted to the server using UTF-8 charset, per the W3C XMLHTTPRequest standard. The data option can contain either a query string of the form key1=value1&key2=value2 , or a map of the form {key1: 'value1', key2: 'value2'} . If the latter form is used, the data is converted into a query string using jQuery.param() before it is sent. This processing can be circumvented by setting processData to false . The processing might be undesirable if you wish to send an XML object to the server; in this case, change the contentType option from application/x-www-form-urlencoded to a more appropriate MIME type. Web application firewalls that may be configured to detect exploitation of such data – attempts at SQL injection, for example – must be able to parse this data in order to make a determination regarding the legitimacy of the input. Similarly, application delivery controllers and load balancing services configured to perform application layer switching based on data values or submission URI will also need to be able to parse and act upon that data. That requires an understanding of how jQuery formats its data and what to expect, such that it can be parsed, interpreted and processed. By understanding jQuery – and other developer toolkits and standards used to exchange data – infrastructure service providers and vendors can more readily provide security and delivery policies tailored to those formats natively, which greatly reduces the impact of intermediate processing on performance while ensuring the secure, healthy delivery of applications. API Jabberwocky: You Say Tomay-to and I Say Potah-to OpenAjax Metadata 1.0 and the Adobe Dreamweaver Widget Browser OpenAjax Alliance AJAX-based Dojo Toolkit The Stealthy Ascendancy of JSON JSON Continues its Winning Streak Over XML JSON versus XML: Your Choice Matters More Than You Think I am in your HTTP headers, attacking your application The Web 2.0 API: From collaborating to compromised IT as a Service: A Stateless Infrastructure Architecture Model JSON Activity Streams and the Other Consumerization of IT350Views0likes0Comments
iRule checking multiple "active_members" help
Hi All, I'm currently building on-top of a couple of iRules I developed a while ago for our maintenance page - I'm extending the behaviour to also trigger a site failure page if everything fails (non-controlled take-down) To do this I need to check the state of TWO pools -I would have assumed that this would be quite trivial with a simple logic operator... however I get the following error when attempting to Apply the iRule to a Virtual-server (so its already passed the first set of validation when saving the irule initially): **_01070151:3: Rule [/Common/OopsPage2] error: Unable to find pool (Pool2) referenced at line 3: [active_members "Pool2"]_** I've tried a couple of variations with different parenthesise combinations: if { [active_members "Pool1" ] < 1 and [active_members "Pool2" ] > 0 } { AND if { ([active_members "Pool1" ] < 1) and ([active_members "Pool2" ] > 0) } { Can someone spot the rookie mistake that I'm making? This works if I specify a single Pool to check. I am developing on LTM 11.1.0... I might also try this on 10.2.3 Thanks in advance for your help... Regards, Patrick365Views0likes4Comments
11.4 iapp namespace
Hi, I'm developing some iApp templates based on the f5.http. I need to be able to let the user decide if a specific pool member is enabled or disabled when the iApp is deployed. I already added in the presentation section a choice field to enable or disable the member: table members { editchoice addr display "large" tcl { package require iapp 1.0.0 return [iapp::get_items ltm node] } string port display "small" required default "80" validator "PortNumber" string connection_limit display "small" required default "0" validator "NonNegativeNumber" optional ( lb_method == "ratio-member" || lb_method == "ratio-node" || lb_method == "ratio-session" || lb_method == "ratio-least-connections-member" || lb_method == "ratio-least-connections-node" || lb_method == "dynamic-ratio-member" || lb_method == "dynamic-ratio-node" ) { string ratio default "1" validator "NonNegativeNumber" display "small" } optional ( options.advanced == "yes" && use_pga == "yes" ) { string priority default "0" required validator "NonNegativeNumber" display "small" } optional ( options.advanced == "yes" ) { choice state display "xlarge" default "enabled" } } The pool is configured with this statement in the template: array set pool_arr { 1,0 { [iapp::conf create ltm pool ${app}_pool \ [iapp::substa pool_ramp_pga_arr($advanced,$do_slow_ramp,$do_pga)] \ [iapp::substa pool_lb_queue_arr($advanced)] \ [iapp::substa monitor_arr($new_pool,$new_monitor,$advanced)] \ [iapp::pool_members $::pool__members]] \ [iapp::conf modify ltm pool ${app}_pool \ ] } 0,0 { [expr { $::net__server_mode ne "tunnel" ? \ $::pool__pool_to_use : $::pool__pool_to_use_wom }] } * { none translate-address disabled } } As the pool members are configured with the "iapp::pool_members" routine, it would be best if this configures the state of the member too. I haven't found the source of this routine so i don't know if it is capable of doing this. Is there any documentation on the iapp:: namespace and it's source code? If the routine is not capable of setting the state - any ideas on how to configure the member state besides iterating over the $::pool__members variable? Greetings, Eric278Views0likes2CommentsProtecting against DDoS attack
Dear Community, I need help from application security experts and seasoned web developers. We are getting DDoS attacks on the following requests. This attack is targetting our SMS gateway; resulting in triggerig thousands of SMSs. Please inform which kind of protections we can introduce in application level / application code level to protect against this DDoS attack. DDoS Request Sample: POST xyz.com/api/otp/asdf HTTP/1.1 Host: xyz.com Content-Length: 32 Sec-Ch-Ua: " Not A;Brand";v="99", "Chromium";v="90" Accept: application/json, text/plain, */* Authorization: *********** Accept-Language: ar Sec-Ch-Ua-Mobile: ?0 User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36 Content-Type: application/json Origin: http://abc.com Sec-Fetch-Site: same-site Sec-Fetch-Mode: cors Sec-Fetch-Dest: empty Referer:http://abc.com Accept-Encoding: gzip, deflate Connection: close {"mobileNumber":"123456789"} Warm Regards946Views0likes1CommentPreventing DDoS attacks on SMS URL
Dear Community, I am facing DDoS attacks on one of our application. The attacker is sending hundred of requests to a URL, which is consuming all of our SMS quota. The attack is originating from multiple IPs. Please inform how I can protect this application API from this kind of DDoS attack from appliation code level. I need help from application security experts and web developers. https://abc.comis frontend & xyz.com is backend api Sample of DDoS reqeust: POST /asdf/service/sendmobilecode HTTP/1.1 Host:xyz.com Authorization: *********** User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36 Content-Type: application/json Origin:https://abc.com Referer:https://abc.com/ {"number":"91234567890"} Kind Regards1.1KViews0likes3CommentsProgrammability in the Network: Canary Deployments
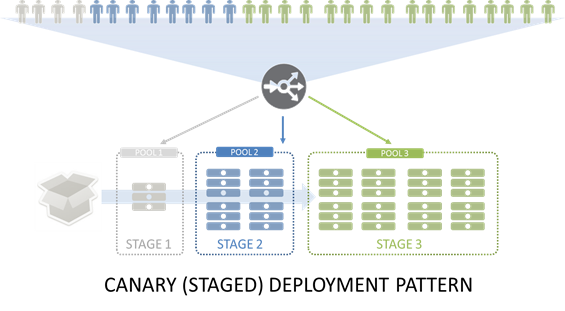
#devops The canary deployment pattern is another means of enabling continuous delivery. Deployment patterns (or as I like to call them of late, devops patterns) are good examples of how devops can put into place systems and tools that enable continuous delivery to be, well, continuous. The goal of these patterns is, for the most part, to make sure operations can smoothly move features, functions, releases or applications into production. We've previously looked at the Blue Green deployment pattern and today we're going to look at a variation: Canary deployments. Canary deployments are applicable when you're running a cluster of servers. In other words, you've got lots and lots of (probably active right now while you're considering pushing that next release) users. What you don't want is to do the traditional "we're sorry, we're down for maintenance, here's a picture of a funny squirrel to amuse you while you wait" maintenance page. You want to be able to roll out the new release without disruption. Yeah, that's quite the ask, isn't it? The Canary deployment pattern is an incremental upgrade methodology. First, the build is pushed to a small set of servers to which only a select group of users are directed. If that goes well, the release is pushed to a larger set of servers with a limited set of users. Finally, if that goes well, then the release is pushed out to all servers and all users. If issues occur at any stage, the release is halted - it goes no further. Hence the naming of the pattern - after the miner's canary, used because "its demise provided a warning of dangerous levels of toxic gases". The trick to implementing this pattern is two fold: first, being able to group the servers used in each step into discrete pools and second, the ability to direct specific sets of users to the appropriate pools. Both capabilities requires the ability to execute some logic to perform user-based load balancing. Nolio, in its first Devops Best Practices video, implements Canary deployments by manipulating the pools of servers at the load balancing tier, removing them to upgrade and then reinserting them for testing before moving onto the next phase. If your load balancing solution is programmable, there's no need to actually remove them as you can simply insert logic to remove them from being selected until they've been upgraded. You can also then insert the logic to determine which users are directed to which pool of servers. If the load balancing platform is really programmable, you can even extend that to determination to querying a database to determine user inclusion in certain groups, such as those you might use to perform AB testing. Such logic might base the decision on IP address (not the best option but an option) or later, when you're actually rolling out to a percentage of users you can write logic that randomly selects users based on location or their user name - like sharding, only in reverse - or pretty much anything you can think of. You can even split that further if you're rolling out an update to an API that's used by both mobile and traditional clients, to catch both or neither or specific types in an orderly fashion so you can test methodically - because you want to test methodically when you're using live users as test subjects. The beauty of this pattern is that allows continuous delivery. Users are never disrupted (if you do it right) and the upgrade occurs in a safely staged, incremental fashion. That enables you to back out quickly if necessary, because you do have a back button plan, right? Right?807Views1like1Comment
How to develop a second factor authentication plugin/extension?
Very new to BIG-IP I am trying to port an extension for second factor authentication written for PingFederate. There I have to create a jar and deploy it in PF. Then I can login as admin and configure it as a policy: Login using AD, on success, trigger my plugin which does the OTP and then allow access to the resource. How do I do something similar in BIG-IP? Is APM > AAA Servers the right way to do this?616Views0likes7Comments
iControl REST 101: Modifying Objects
So far in this series we’ve shown you how to connect to iControl REST via cURL, how to list objects on the device (which is probably the most used command for most APIs, including ours), and how to add objects. So you’re currently able to get a system up and running and configure new services on your BIG-IP. What if, however, you want to modify things that are already running? For that, you need a modify command. Enter PUT. Remember that in REST based architectures the API is able to determine what type of action you’re performing, and thereby the arguments and structure it should expect to parse coming in, based on the type of HTTP(S) transaction. For us a GET is a list, a POST is an add, and to modify things, you use PUT. This allows the system to understand that you’re going to reference an object that already exists, and modify some of the contents. It is important that the API back end can tell the difference. If you just tried to do another POST with only the arguments you wanted to change, it would fail because you wouldn’t meet the minimum requirements. Without a PUT, you’d have to do a list on the object, save all the configuration options already on the system for that object, modify just the one you wanted to change in your memory structure, delete the object on the system, and then POST all of that data, including the one or two modified fields, back to the device. That’s way too much work. Instead, let’s just learn how to modify, shall we? Fortunately it’s simple. All you need to do is format your cURL request with a PUT and the data you want to modify, and you’re all set. First let’s list the object we want to modify, so you can see what it looks like as it sits on the box currently. For that we go back to our list command: curl -sk -u admin:admin https://dev.rest.box/mgmt/tm/net/self/cw_test2 | jq . So that’s what the object looks like Now what if we want to simply make that existing self IP address available for more than one port? We can use the “allowService” flag to do this. By setting it to “all” we’ll allow that IP to answer on any port, rather than just a specific one, thereby opening up our config a bit. So we have the object we want to modify as well as the attribute we want to modify for that object. All we need now is to send the command to do the work. Fortunately this is pretty easy, as I mentioned before. You use the same cURL structure as always with the –sk and user:pass supplied. This will look nearly identical to the add command with the changes being that we use the “PUT” method instead of “POST” and we only supply the one item we’re modifying about the object. It looks like this: curl -sk -u admin:admin https://dev.rest.box/mgmt/tm/net/self/cw_test2 -H "Content-Type: application/json" -X PUT -d "{\"allowService\":\"all\"}" | jq . Notice that I’m still piping the output to jq here. This is because the response from the API when running most commands such as POST and PUT is actually quite useful. Here’s what I get when I run the above command: As you can see this returns the entire, new output of the object, including the piece that got modified. In this case it’s the sixth line of output, including the brace lines. What used to be the line defining the vlan is now "allowService": "all", just like we wanted. So there you have it, modifying objects on the BIG-IP remotely doesn’t get much easier than that. Armed with this knowledge on top of what we’ve covered in previous installments you’ll be able to tackle 90% of the challenges you might encounter. For our next and penultimate edition of this series we’ll cover the delete command, which should round out the methods you’ll need for the general application of the new iControl REST API.882Views1like8CommentsDNS Profile Benefits in iRules
I released an article a while back on the DNS services architecture now built in to BIG-IP, as well as a solution article that showed some fancy DNS tricks utilizing the architecture to black hole malicious DNS requests. What might be lost in those articles is the difference maker the dns profile makes in using iRules to return DNS responses. I was working on a little project earlier this week and the VM I am hosting requires a single DNS response to a single question. The problem is that I don't have the particular fqdn defined in an external or internal name server. Adding the fqdn to either is problematic: Adding the FQDN to the external name server would require adding an internal view to bind, which adds risk and complexity. Adding the FQDN to the internal name server would require adding external zones to my internal server, which adds unnecessary complexity. So as I wasn't going down either of those roads...I had to find an alternate solution. Thankfully, I have BIG-IP VE at my disposal, and therefore, iRules. The DNS profile exposes in iRules the DNS:: namespace, and with it, native decodes for all the fields in requests/responses. The iRule, with the DNS namespace, is trivial: when DNS_REQUEST { if { [IP::addr [IP::remote_addr] equals 192.168.1.0/24] && ([DNS::question name] equals "www.mytest.com") } { DNS::answer insert "[DNS::question name]. 111 [DNS::question class] [DNS::question type] 192.168.1.200" DNS::return } else ( discard } } However, after trying to save the iRule, I realized I'm not licensed for dns services on my BIG-IP VE, so that path wouldn't work. So I took a packet capture of some local dns traffic on my desktop and started mapping the fields and preparing to settle in for some serious binary scan/format work, but then remembered there were already some iRules out in the codeshare that I though might get me started. Natty76's Fast DNS 2 seemed to fit the bill. So with just a little customization, I was up and running with no issues. But notice the amount of work required (both by author and by system resources) to make this happen when compared with the above iRule. when RULE_INIT priority 1 { # Domain Name = www mytest com set static::domain "www.mytest.com" # IP address in answer section (type A) set static::answer_string "192.168.1.200" } when RULE_INIT { # Header generation (in hexadecimal) # qr(1) opcode(0000) AA(1) TC(0) RD(1) RA(1) Z(000) RCODE(0000) set static::header "8580" # 1 question, X answer, 0 NS, 0 Addition set static::answer_record [format %04x [llength $static::answer_string]] set static::header "${static::header}0001${static::answer_record}00000000" # generate domain binary string set static::domainhex "" foreach static::d [split $static::domain "."] { set static::l [string length $static::d] scan $static::l %d static::h append static::domainhex [format %02x $static::h] foreach static::n [split $static::d ""] { scan $static::n %c static::h append static::domainhex [format %02x $static::h] } } set static::domainbin [binary format H* $static::domainhex] append static::domainhex 00 set static::answerhead $static::domainhex # Type = A set static::answerhead "${static::answerhead}0001" # Class = IN set static::answerhead "${static::answerhead}0001" # TTL = 1 day set static::answerhead "${static::answerhead}00015180" # Data length = 4 set static::answerhead "${static::answerhead}0004" set static::answer "" foreach static::a $static::answer_string { scan $static::a "%d.%d.%d.%d" a b c d append static::answer "${static::answerhead}[format %02x%02x%02x%02x $a $b $c $d]" } } when CLIENT_DATA { if { [IP::addr [IP::client_addr] equals 192.168.1.0/22] } { binary scan [UDP::payload] H4@12A*@12H* id dname question set dname [string tolower [getfield $dname \x00 1 ] ] switch -glob $dname \ $static::domainbin { #log local0. "match" set hex ${id}${static::header}${question}${static::answer} set payload [binary format H* $hex ] # to drop only a packet and keep UDP connection, use UDP::drop drop UDP::respond $payload } \ default { #log local0. "does not match" } } else { discard } } No native decode means you have to do all the decoding work of the protocol yourself. I don't get to share "from the trenches" as much as I used to, but this was too good a demonstration to pass up.390Views0likes3Comments20 Lines or Less #1
Yesterday I got an idea for what I think will be a cool new series that I wanted to bring to the community via my blog. I call it "20 lines or less". My thought is to pose a simple question: "What can you do via an iRule in 20 lines or less?". Each week I'll find some cool examples of iRules doing fun things in less than 21 lines of code, not counting white spaces or comments, round them up, and post them here. Not only will this give the community lots of cool examples of what iRules can do with relative ease, but I'm hoping it will continue to show just how flexible and light-weight this technology is - not to mention just plain cool. I invite you to follow along, learn what you can and please, if you have suggestions, contributions, or feedback of any kind, don't hesitate to comment, email, IM, whatever. You know how to get a hold of me...please do. ;) I'd love to have a member contributed version of this once a month or quarter or ... whatever if you guys start feeding me your cool, short iRules. Ok, so without further adieu, here we go. The inaugural edition of 20 Lines or Less. For this first edition I wanted to highlight some of the things that have already been contributed by the awesome community here at DevCentral. So I pulled up the Code Share and started reading. I was quite happy to see that I couldn't even get halfway through the list of awesome iRule contributions before I found 5 entries that were neat, and under 20 lines (These are actually almost all under 10 lines of code - wow!) Kudos to the contributors. I'll grab another bunch next week to keep highlighting what we've got already! Cipher Strength Pool Selection Ever want to check the type of encryption your users are using before allowing them into your most secure content? Here's your solution. when HTTP_REQUEST { log local0. "[IP::remote_addr]: SSL cipher strength is [SSL::cipher bits]" if { [SSL::cipher bits] < 128 }{ pool weak_encryption_pool } else { pool strong_encryption_pool } } Clone Pool Based On URI Need to clone some of your traffic to a second pool, based on the incoming URI? Here you go... when HTTP_REQUEST { if { [HTTP::uri] starts_with "/clone_me" } { pool real_pool clone pool clone_pool } else { pool real_pool } } Cache No POST Have you been looking for a way to avoid sending those POST responses to your RAMCache module? You're welcome. when HTTP_REQUEST { if { [HTTP::method] equals "POST" } { CACHE::disable } else { CACHE::enable } } Access Control Based on IP Here's a great example of blocking unwelcome IP addresses from accessing your network and only allowing those Client-IPs that you have deemed trusted. when CLIENT_ACCEPTED { if { [matchclass [IP::client_addr] equals $::trustedAddresses] }{ #Uncomment the line below to turn on logging. #log local0. "Valid client IP: [IP::client_addr] - forwarding traffic" forward } else { #Uncomment the line below to turn on logging. #log local0. "Invalid client IP: [IP::client_addr] - discarding" discard } } Content Type Tracking If you're looking to keep track of the different types of content you're serving, this iRule can help in a big way. # First, create statistics profile named "ContentType" with following entries: # HTML # Images # Scripts # Documents # Stylesheets # Other # Now associate this Statistics Profile to the virtual server. Then apply the following iRule. # To view the results, go to Statistics -> Profiles - Statistics when HTTP_RESPONSE { switch -glob [HTTP::header "Content-type"] { image/* { STATS::incr "ContentType" "Images" } text/html { STATS::incr "ContentType" "HTML" } text/css { STATS::incr "ContentType" "Stylesheets" } *javascript { STATS::incr "ContentType" "Scripts" } text/vbscript { STATS::incr "ContentType" "Scripts" } application/pdf { STATS::incr "ContentType" "Documents" } application/msword { STATS::incr "ContentType" "Documents" } application/*powerpoint { STATS::incr "ContentType" "Documents" } application/*excel { STATS::incr "ContentType" "Documents" } default { STATS::incr "ContentType" "Other" } } } There you have it, the first edition of "20 Lines or Less"! I hope you enjoyed it...I sure did. If you've got feedback or examples to be featured in future editions, let me know. #Colin4.5KViews1like1Comment