All I want for Christmas is a hybrid cloud
********** Dear Santa, I hope you and the reindeers are as excited as I am about Christmas! Make sure you get plenty of rest between now and then, so you can deliver all those lovely presents all over the world on Christmas Eve. I’ve thought a lot about what I want for Christmas, and have finally made a decision. This Christmas all I want is a hybrid cloud. I’ve heard so much about them, and lots of people either already have them or are getting them soon, and I want to join the fun! I really want a hybrid cloud because of the benefits it brings: increased scalability, improved security, better resource allocation, better availability and resiliency, and it’s much more cost-effective. And who wouldn’t want that! I hope I wake up on Christmas morning with a lovely new hybrid cloud infrastructure! I just hope you can fit it on your sleigh. ********** I think Santa’s got some work to do to get me a hybrid cloud infrastructure for Christmas! But the point made above about lots of people going down the hybrid route is true: the recent Right Scale 2015 State of the Cloud Report revealed that 82% of businesses have a hybrid cloud strategy in place. That figure is up from 74% the year before. That’s because businesses are attracted by the cost savings it can offer, as well as the other benefits mentioned in my letter to Santa above. But they also don’t want to trade-off control in order to realise these benefits; they want to maintain the same visibility, security and control of a traditional infrastructure. The key to a good hybrid environment is the ability to unify all the hardware, software and managed services resources that make up both on-premises and cloud environments. This combination of physical and virtual resources makes it easier to transition workloads to the cloud as and when needed. Now, cloud is regularly considered a security risk for organisations. And that’s fair, to some extent: cloud computing and increased mobility has meant enterprise perimeters have changed; applications are now accessed from a variety of environments and from different devices (both corporate and personal) and locations. But having a hybrid environment means security processes and protocols that apply on-premises can be extended to the cloud, protecting your users - and your data - wherever they are. This approach not only secures cloud-based, web-based, and virtual applications but also ensures high availability and reliable access. Hybrid clouds are the best of both worlds, all the benefits of cloud computing without sacrificing security, flexibility, or cost savings. However, organisations must consider what it takes to ensure applications and services there are treated the same way as on-premises infrastructure, so they can embrace a hybrid cloud with the same confidence as they approach their own data centre. Thanks Santa, and have a great Christmas folks!362Views0likes0Comments
Bringing Consistency to Hybrid Cloud
The term Hybrid Cloud is at the same stage that ‘Cloud’ was a few years ago: Used everywhere but generally misrepresented. What most people have is basically a mix of on-premises, cloud based and SaaS applications, often with only limited interaction between them. And that’s OK. It represents a stage on our journey to a more integrated, flexible service delivery architecture where, eventually, policy will probably automatically determine where an application workload runs. What we need to know is what path we need to take to get from here to there with the minimum of wasted effort and dead ends. One of the things that seems necessary to me is having ubiquitous and consistent application services in all your locations. What are application services? They are all the things that are neither the application or the base infrastructure. Firewalls, application delivery controllers, protocol gateways: these are all services that help to make an application more salable, secure or available. To really create a flexible environment, we need to know that an application can be deployed in our chosen location and that it will have the services it needs to work. From an operational perspective we want consistency and homogenous management across our various infrastructures, a common set of tools and processes. One way to do this is to choose vendors that can supply services wherever we are going to need them, at the scale we require. This, I think is a significant advantage of F5. Whether you need a high capacity Viprion for a high performance application running on dedicated hardware, or a farm of lab-edition BIG-IP’s running in AWS for your test and development, and anything in between, we will be there with you. Providing our range of security, availability and optimization services wherever your applications need them, and helping you turn hybrid cloud into reality.164Views0likes0Comments
Cloud bursting, the hybrid cloud, and why cloud-agnostic load balancers matter
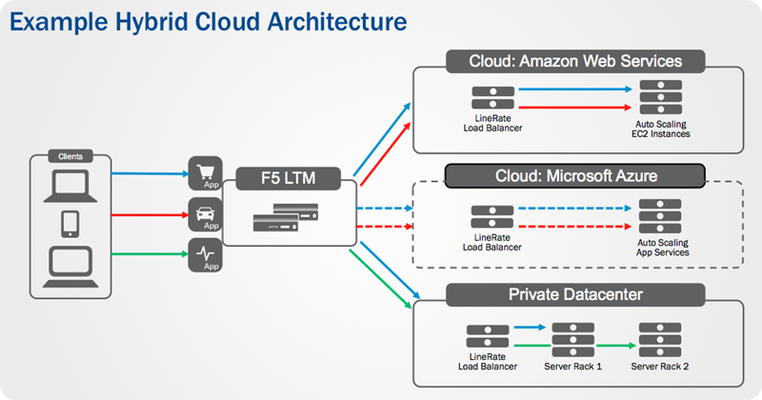
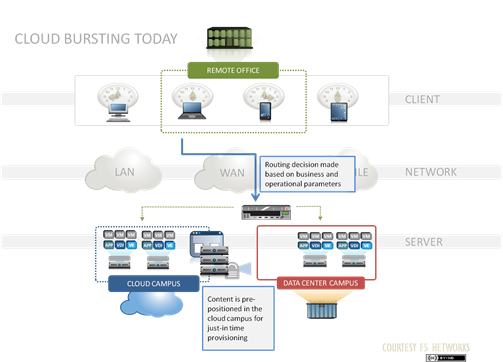
Cloud Bursting and the Hybrid Cloud When researching cloud bursting, there are many directions Google may take you. Perhaps you come across services for airplanes that attempt to turn cloudy wedding days into memorable events. Perhaps you'd rather opt for a service that helps your IT organization avoid rainy days. Enter cloud bursting ... yes, the one involving computers and networks instead of airplanes. Cloud bursting is a term that has been around in the tech realm for quite a few years. It, in essence, is the ability to allocate resources across various public and private clouds as an organization's needs change. These needs could be economic drivers such as Cloud 2 having lower cost than Cloud 1, or perhaps capacity drivers where additional resources are needed during business hours to handle traffic. For intelligent applications, other interesting things are possible with cloud bursting where, for example, demand in a geographical region suddenly needs capacity that is not local to the primary, private cloud. Here, one can spin up resources to locally serve the demand and provide a better user experience.Nathan Pearcesummarizes some of the aspects of cloud bursting inthis minute long video, which is a great resource to remind oneself of some of the nuances of this architecture. While Cloud Bursting is a term that is generally accepted by the industry as an "on-demand capacity burst,"Lori MacVittiepoints out that this architectural solution eventually leads to aHybrid Cloudwhere multiple compute centers are employed to serve demand among both private-based resources are and public-based resources, or clouds, all the time. The primary driver for this: practically speaking,there are limitations around how fast data that is critical to one's application (think databases, for example) can be replicated across the internet to different data centers.Thus, the promises of "on-demand" cloud bursting scenarios may be short lived, eventually leaning in favor of multiple "always-on compute capacity centers"as loads increase for a given application.In any case, it is important to understand thatthat multiple locations, across multiple clouds will ultimately be serving application content in the not-too-distant future. An example hybrid cloud architecture where services are deployed across multiple clouds. The "application stack" remains the same, using LineRate in each cloud to balance the local application, while a BIG-IP Local Traffic Manager balances application requests across all of clouds. Advantages of cloud-agnostic Load Balancing As one might conclude from the Cloud Bursting and Hybrid Cloud discussion above, having multiple clouds running an application creates a need for user requests to be distributed among the resources and for automated systems to be able to control application access and flow. In order to provide the best control over how one's application behaves, it is optimal to use a load balancer to serve requests. No DNS or network routing changes need to be made and clients continue using the application as they always did as resources come online or go offline; many times, too, these load balancers offer advanced functionality alongside the load balancing service that provide additional value to the application. Having a load balancer that operates the same way no matter where it is deployed becomes important when resources are distributed among many locations. Understanding expectations around configuration, management, reporting, and behavior of a system limits issues for application deployments and discrepancies between how one platform behaves versus another. With a load balancer like F5's LineRate product line, anyone can programmatically manage the servers providing an application to users. Leveraging this programatic control, application providers have an easy way spin up and down capacity in any arbitrary cloud, retain a familiar yet powerful feature-set for their load balancer, ultimately redistribute resources for an application, and provide a seamless experience back to the user. No matter where the load balancer deployment is, LineRate can work hand-in-hand with any web service provider, whether considered a cloud or not. Your data, and perhaps more importantly cost-centers, are no longer locked down to one vendor or one location. With the right application logic paired with LineRate Precision's scripting engine, an application can dynamically react to take advantage of market pricing or general capacity needs. Consider the following scenarios where cloud-agnostic load balancer have advantages over vendor-specific ones: Economic Drivers Time-dependent instance pricing Spot instances with much lower cost becoming available at night Example: my startup's billing system can take advantage in better pricing per unit of work in the public cloud at night versus the private datacenter Multiple vendor instance pricing Cloud 2 just dropped their high-memory instance pricing lower than Cloud 1's Example: Useful for your workload during normal business hours; My application's primary workload is migrated to Cloud 2 with a simple config change Competition Having multiple cloud deployments simultaneously increases competition, and thusyour organization's negotiated pricing contracts become more attractiveover time Computational Drivers Traffic Spikes Someone in marketing just tweeted about our new product. All of a sudden, the web servers that traditionally handled all the loads thrown at them just fine are gettingslashdottedby people all around North America placing orders. Instead of having humans react to the load and spin up new instances to handle the load - or even worse: doing nothing - your LineRate system and application worked hand-in-hand to spin up a few instances in Microsoft Azure's Texas location and a few more in Amazon's Virginia region. This helps you distribute requests from geographically diverse locations: your existing datacenter in Oregon, the central US Microsoft Cloud, and the east-coast based Amazon Cloud. Orders continue to pour in without any system downtime, or worse: lost customers. Compute Orchestration A mission-critical application in your organization's private cloud unexpectedly needs extra computer power, but needs to stay internal for compliance reasons. Fortunately, your application can spin up public cloud instances and migrate traffic out of the private datacenter without affecting any users or data integrity. Your LineRate instance reaches out to Amazon to boot instances and migrate important data. More importantly, application developers and system administrators don't even realize the application has migrated since everything behaves exactly the same in the cloud location. Once the cloud systems boot, alerts are made to F5's LTM and LineRate instances that migrate traffic to the new servers, allowing the mission-critical app to compute away. You just saved the day! The benefit to having a cloud-agnostic load balancing solution for connecting users with an organization's applications not only provides a unified user experience, but provides powerful, unified way of controlling the application for its administrators as well. If all of a sudden an application needs to be moved from, say, aprivate datacenter with a 100 Mbps connection to a public cloud with a GigE connection, this can easily be done without having to relearn a new load balancing solution. F5's LineRate product is available for bare-metal deployments on x86 hardware, virtual machine deployments, and has recently deployed anAmazon Machine Image (AMI). All of these deployment types leverage the same familiar, powerful tools that LineRate offers:lightweight and scalable load balancing, modern management through its intuitive GUI or the industry-standard CLI, and automated control via itscomprehensive REST API.LineRate Point Load Balancerprovides hardened, enterprise-grade load balancing and availability services whereasLineRate Precision Load Balanceradds powerful Node.js programmability, enabling developers and DevOps teams to leveragethousands of Node.js modulesto easily create custom controlsfor application network traffic. Learn about some of LineRate'sadvanced scripting and functionalityhere, ortry it out for freeto see if LineRate is the right cloud-agnostic load balancing solution for your organization.876Views0likes0CommentsThe Three Reasons Hybrid Clouds Will Dominate
In the short term, hybrid cloud is going to be the cloud computing model of choice. Amidst all the disconnect at CloudConnect regarding standards and where “cloud” is going was an undercurrent of adoption of what most have come to refer to as a “hybrid cloud computing” model. This model essentially “extends” the data center into “the cloud” and takes advantage of less expensive compute resources on-demand. What’s interesting is that the use of this cheaper compute is the granularity of on-demand. The time interval for which resources are utilized is measured more in project timelines than in minutes or even hours. Organizations need additional compute for lab and quality assurance efforts, for certification testing, for production applications for which budget is limited. These are not snap decisions but rather methodically planned steps along the project management lifecycle. It is on-demand in the sense that it’s “when the organization needs it”, and in the sense that it’s certainly faster than the traditional compute resource acquisition process, which can take weeks or even months. Also mentioned more than once by multiple panelists and speakers was the notion of separating workload such that corporate data remains in the local data center while presentation layers and GUIs move into the cloud computing environment for optimal use of available compute resources. This model works well and addresses issues with data security and privacy, a constant top concern in surveys and polls regarding inhibitors of cloud computing. It’s not just the talk at the conference that makes such a conclusion probabilistic. An Evans Data developer survey last year indicated that more than 60 percent of developers would be focusing on hybrid cloud computing in 2010. Results of the Evans Data Cloud Development Survey, released Jan. 12, show that 61 percent of the more than 400 developers polled said some portion of their organizations' IT resources "will move to the public cloud within the next year," Evans Data said. "However, over 87 percent [of the developers] say half or less then half of their resources will move ... As a result, the hybrid cloud is set to dominate the coming IT landscape." There are three reasons why this model will become the de facto standard strategy for leveraging cloud computing, at least in the short term and probably for longer than some pundits (and providers) hope.334Views0likes2Comments
Don’t believe a word I say about Cloud – listen to my customer!
Everbridge is a critical communications platform provider - that’s what it says on their website. What their website won’t tell you is that the Everbridge IT team are a collective of experts when it comes to consuming cloud-based services, and they’ve put together a solid strategy that matches the high expectations of their customers without introducing risk to their business. Critical Communications Platform what? During critical events, Everbridge removes global, regional, and technology barriers, enabling organizations to quickly communicate and collaborate within the right context. They provide the most secure, comprehensive, and resilient platform on the market to improve critical communications and increase situational intelligence for diverse industries, including corporations, state and local government, healthcare, financial services, and higher education. The services provided by Everbridge save lives, and as you’ve likely worked out for yourself they do not have the luxury of backing out of deployments, or rescheduling the migration of a service to a cloud platform. Their business requires them to react, quickly and reliably, providing a consistent platform where ever required, anywhere in the world. How do you do it? Everbridge deliver their applications and services through a common set of application delivery policies across all of their chosen platforms: hardware and software, running on both private and public infrastructure. By using F5 for their application delivery, security and DNS services Everbridge is able to deploy predefined policies anywhere they workload is needed, anywhere in the world. This model eliminates the requirement of them to learn and manage an array of cloud provider services, and avoid adding unnecessary complexity deployment and administrative complexity, for their application availability, security and performance requirements. Anyway, don’t take my word for it, here’s a short video from Everbridge explaining how to reduce the associated risks with and to simplify the journey to cloud.225Views0likes0CommentsHighly Available Hybrid
Achieving the ultimate ‘Five Nines’ of web site availability (around 5 minutes of downtime a year) has been a goal of many organizations since the beginning of the internet era. There are several ways to accomplish this but essentially a few principles apply. Eliminate single points of failure by adding redundancy so if one component fails, the entire system still works. Have reliable crossover to the duplicate systems so they are ready when needed. And have the ability to detect failures as they occur so proper action can be taken. If the first two are in place, hopefully you never see a failure but maintenance is a must. BIG-IP high availability (HA) functionality, such as connection mirroring, configuration synchronization, and network failover, allow core system services to be available for BIG-IP to manage in the event that a particular application instance becomes unavailable. Organizations can synchronize BIG-IP configurations across data centers to ensure the most up to date policy is being enforced throughout the entire infrastructure. In addition, BIG-IP itself can be deployed as a redundant system either in active/standby or active/active mode. Web applications come in all shapes and sizes from static to dynamic, from simple to complex from specific to general. No matter the size, availability is important to support the customers and the business. The most basic high-availability architecture is the typical 3-tier design. A pair of ADCs in the DMZ terminates the connection; they in turn intelligently distribute the client request to a pool (multiple) of application servers which then query the database servers for the appropriate content. Each tier has redundant servers so in the event of a server outage, the others take the load and the system stays available. This is a tried and true design for most operations and provides resilient application availability within a typical data center. But fault tolerance between two data centers is even more reliable than multiple servers in a single location, simply because that one data center is a single point of failure. A hybrid data center approach allows organizations to not only distribute their applications when it makes sense but can also provide global fault tolerance to the system overall. Depending on how an organization’s disaster recovery infrastructure is designed, this can be an active site, a hot-standby, some leased hosting space, a cloud provider or some other contained compute location. As soon as that server, application, or even location starts to have trouble, organizations can seamlessly maneuver around the issue and continue to deliver their applications. Driven by applications and workloads, a hybrid data center is really a technology strategy of the entire infrastructure mix of on premise and off-premise data compute resources. IT workloads reside in conventional enterprise IT (legacy systems), an on premise private cloud (mission critical apps), at a third-party off-premise location (managed, hosting or cloud provider) or a combination of all three. The various combinations of hybrid data center types can be as diverse as the industries that use them. Enterprises probably already have some level of hybrid, even if it is a mix of owned space plus SaaS. Enterprises typically like to keep sensitive assets in house but have started to migrate workloads to hybrid data centers. Financial industries might have different requirements than retail. Startups might start completely with a cloud based service and then begin to build their own facility if needed. Mobile app developers, particularly games, often use the cloud for development and then bring it in-house once it is released. Enterprises, on the other hand, have (historically) developed in house and then pushed out to a data center when ready. The variants of industries, situations and challenges the hybrid approach can address is vast. Manage services rather than boxes. ps Related Hybrid DDoS Needs Hybrid Defense The Conspecific Hybrid Cloud The future of cloud is hybrid ... and seamless Hybrid–The New Normal Hybrid Architectures Do Not Require Private Cloud Technorati Tags: f5,hybrid,cloud,datacenter,applications,availability,silva Connect with Peter: Connect with F5:261Views0likes0CommentsThe Dynamic Data Center: Cloud's Overlooked Little Brother
It may be heresy, but not every organization needs or desires all the benefits of cloud. There are multiple trends putting pressure on IT today to radically change the way they operate. From SDN to cloud, market pressure on organizations to adopt new technological models or utterly fail is immense. That's not to say that new technological models aren't valuable or won't fulfill promises to add value, but it is to say that the market often overestimates the urgency with which organizations must view emerging technology. Too, mired in its own importance and benefits, markets often overlook that not every organization has the same needs or goals or business drivers. After all, everyone wants to reduce their costs and simplify provisioning processes! And yet goals can often be met through application of other technologies that carry less risk, which is another factor in the overall enterprise adoption formula – and one that's often overlooked. DYNAMIC DATA CENTER versus cloud computing There are two models competing for data center attention today: dynamic data center and cloud computing. They are closely related, and both promise similar benefits with cloud computing offering "above and beyond" benefits that may or may not be needed or desired by organizations in search of efficiency. The dynamic data center originates with the same premises that drive cloud computing: the static, inflexible data center models of the past inhibit growth, promote inefficiency, and are fraught with operational risk. Both seek to address these issues with more flexible, dynamic models of provisioning, scale and application deployment. The differences are actually quite subtle. The dynamic data center is focused on NOC and administration, with enabling elasticity and shared infrastructure services that improve efficiency and decrease time to market. Cloud computing, even private cloud, is focused on the tenant and enabling for them self-service capabilities across the entire application deployment lifecycle. A dynamic data center is able to rapidly respond to events because it is integrated and automated to enable responsiveness. Cloud computing is able to rapidly respond to events because it is necessarily must provide entry points into the processes that drive elasticity and provisioning to enable the self-service aspects that have become the hallmark of cloud computing. DATA CENTER TRANSFORMATION: PHASE 4 You may recall the cloud maturity model, comprising five distinct steps of maturation from initial virtualization efforts through a fully cloud-enabled infrastructure. A highly virtualized data center, managed via one of the many available automation and orchestration frameworks, may be considered a dynamic data center. When the operational processes codified by those frameworks are made available as services to consumers (business and developers) within the organization, the model moves from dynamic data center to private cloud. This is where the dynamic data center fits in the overall transformational model. The thing is that some organizations may never desire or need to continue beyond phase 4, the dynamic data center. While cloud computing certainly brings additional benefits to the table, these may be benefits that, when evaluated against the risks and costs to implement (or adopt if it's public) simply do not measure up. And that's okay. These organizations are not some sort of technological pariah because they choose not to embark on a journey toward a destination that does not, in their estimation, offer the value necessary to compel an investment. Their business will not, as too often predicted with an overabundance of hyperbole, disappear or become in danger of being eclipsed by other more agile, younger versions who take to cloud like ducks take to water. If you're not sure about that, consider this employment ad from the most profitable insurance company in 2012, United Health Group – also #22 on the Fortune 500 list – which lists among its requirements "3+ years of COBOL programming." Nuff said. Referenced blogs & articles: Is Your Glass of Cloud Half-Empty or Half-Full? Fortune 500 Snapshot: United Health Group Hybrid Architectures Do Not Require Private Cloud291Views0likes0CommentsAll Your Packets Are Belong to … You?
Yes, even the ones over there, in that there cloud, can be yours. No one argues that networks have not exploded in terms of speeds and feeds in the past decade. What with more consumers (and cows), more companies going “online”, and more content it’d be hard to argue that there’s less traffic out there today than there was even a mere four or five years ago. The increasing pressure put on the network is often mentioned almost in passing, as though merely moving from 10Gbps to 40Gbps to 100Gbps will solve the problem. Move along now, nothing to see here but a higher flow of packets. But that higher density of packets along with greater diversity of content coupled with distribution through cloud computing that’s creating other issues for network services whose purpose it is to collect, analyze, and act upon those packets. IDS, IPS, secure web gateways, voice analyzers, honeypots. There are myriad network infrastructure devices that are tasked with analyzing the content of packets flowing in and out of the data center that find it more and more difficult to scale along with the rapid growth of data on the network. Application Performance Monitoring (APM) systems, as well, often take advantage of port mirroring as a way to collect and analyze intra-system traffic to pinpoint configuration or network issues that may cause performance degradation. These systems need one thing: all your (relevant) packets. The problem is that on most switches, you can designate only a couple of ports as egress span ports and you may have three, four or more devices and systems that need those packets. And Heaven forbid you have a desperate need to later tap into the switch to troubleshoot an urgent issue. The answer in the past has been some highly complex network topologies that are difficult to maintain and not easy to extend when the next system needing all your packets is deployed. Additionally, cloud-deployed applications and systems are not easily included, even though organizations desire the same level of visibility and analysis of those packets as is found in the data center. One answer to these issues is found in what Gartner is calling Network Packet Brokers. One such provider in this space is VSS Monitoring, which recently introduced a new set of solutions to resolve this lack of visibility both in the data center and within the cloud. VSS MONITORING VSS Monitoring has been around since 2006, shipping aggregation and related management products. Now it’s introduced several new products that assist in the goal of collecting packets across the increasingly cloudy landscape and getting them to the right place at the right time, a market being referred to as “Network Packet Brokers (NPB)”. Gartner analysts describe these solutions as consisting of “devices that facilitate monitoring and security technologies to see the traffic which is required for those solutions to work more effectively. They could be called “monitoring switches” “matrix switches” (Application Aware Network Performance Monitoring (NPM) and Network Packet Broker (NPB) research). NPB solutions must be able to perform many-to-many port mapping using a GUI or CLI, filter packets at L2-4, and perform packing slicing and deduplication as well as aggregation and intelligent distribution. This last criteria is an important one, as it allows operators to filter out noise when directing packets to reduce the requirement that analyzers and systems process (and ultimately discard) irrelevant traffic. VSS Monitoring has introduced a set of solutions that meet (and in some cases exceed) the requirements laid out by Gartner (VSS supports L2-7 filtering) and that further expand the scope of such solutions into cloud computing environments: New packet broker appliances -- vBrokers™ Expanded system-level scalability – vMesh™ Topology-level unified management console – vMC™ VSS achieves this inter-cloud monitoring capability by leveraging a proprietary L2 bi-directional protocol for its interconnects called vMesh. Its vBrokers are purpose-built appliances that can interconnect with one another using vMesh to form a virtual network tool optimization fabric . These vBrokers can be deployed across LAN, WAN segments and in a wide variety of cloud network infrastructure environments using the vMesh architecture effectively forming an overlay network over which packets are shared. From there, it’s a matter of dragging and dropping policies and configuration via its vMC unified management console to access network packets on demand and properly direct them based on organizational needs. the VSS’ new vMesh technology can scale out to up to 256 devices and 10,000 and more ports. VSS also provides an Open XML API that encourages integration. Configuration, remote management, metrics, etc… can be achieved via this API. VSS solutions today are not supported by common provisioning and automation frameworks (Chef, Puppet, OpenStack) although that is something that may very well be supported in the future. Still, the ability to reach out into the cloud and direct packets to DC-hosted infrastructure services providing analysis, security, or other functions solves a major issue with managing cloud-deployed applications: visibility. SDN versus NETWORK PACKET BROKERS At first read, this sounds a lot like a suggested SDN (Software-Defined Networking) use case (found on SDN Central) that posits the use of OpenFlow as a Virtual Patch Panel. However, on deeper inspection there are some distinct differences between the two solutions. While both are focused on solving what is essentially a port forwarding problem (port spanning is really just a case of directing ingress packets on one port to more than one egress port) SDN is (today) more disruptive a solution both in the enterprise and in the cloud. While it’s true that with both solutions you need some means to direct ingress packets to the desired egress port, VSS’ solution does not require that the switches in question be OpenFlow enabled (which may be problematic in cloud environments). Additionally, the forwarding mechanism available with OpenFlow is simple forwarding – packet in, packet out. While a more sophisticated forwarding algorithm could certainly be employed, this would require specific code. VSS, on the other hand, enables intelligent forwarding of actionable packets, reducing the amount of irrelevant traffic any given infrastructure solution might need to process. Voice analyzers, for example, need only see VoIP, SIP and related traffic. Such a system doesn’t need to inspect a JSON exchange, nor will it – the packets will be inspected and discarded. Using a more intelligent approach, VSS can intervene and eliminate the overhead associated with inspecting and discarding non-actionable traffic. This offload-like capability improves the capacity and performance of packet analyzing systems. Further more, VSS offers a single-pane of glass management system for monitoring and managing its packet brokers, while an OpenFlow-enabled solution currently does not. This is certainly an area of exploration for SDN and OpenFlow-enabled devices and future value-add for those banking on SDN; admittedly the technology is still very much in its nascent phase and maturation will bring more mature, robust solutions not only in core device support but in management and niche-market solutions. The other issue is deployment in the cloud, as a virtual device. The good news is that Open vSwitch is embedded in many hypervisors and is available as a package for a variety of Linux-based systems. The bad news is that in some cloud environments (like Amazon) these approaches may not be possible to deploy and/or take advantage of, thus rendering an SDN-OpenFlow approach more or less toothless. VSS’ packet broker, vBroker, supports a broad set of physical and virtual environments (i.e. physical and virtual span ports, ability to filter and remove VN-Tags, etc) which enables a wider set of cloud environments to take advantage of the capabilities. That’s not to say the two couldn’t be combined, either. In fact, VSS could be described as “SDN for networking monitoring”, though VSS itself has not chosen to represent its solution this way. But essentially it’s acting in the same manner as SDN – simply confined to a specific area of functionality – monitoring. As I posited in the past, I suspect we’ll continue to see these kinds of “pockets of SDN” capabilities pop up to resolve some pressing issues that simply can’t be addressed by traditional networking methods – or at least can’t be addressed efficiently or in an acceptably rapid manner. In such an architecture (one comprised of controllers at strategic points of control) VSS Monitoring is certainly positioned to act as the control point for managing a broadly distributed monitoring network.265Views0likes0CommentsF5 Friday: Avoiding the Operational Debt of Cloud
#F5CLP F5 Cloud Licensing Program enables #cloud providers to differentiate and accelerate advanced infrastructure service offerings while reducing operational debt for the enterprise If you ask three different people why they are adopting cloud it’s likely you’ll get three different reasons. The rationale for adopting cloud – whether private or public – depends entirely on the strategy IT has in place to address the unique combination of operational and business requirements for their organizations. But one thing seems clear through all these surveys: cloud is here to stay, in one form or another. Those who are “going private” today may “go hybrid” tomorrow. Those who are “in the cloud” today may reverse direction and decide to, as Alan Leinwand puts it so well, “own the base and rent the spike” by going “hybrid.” What the future seems to hold is hybrid architectures, with use of public and private cloud mixed together to provide the best of both worlds. This state of possibility certainly leaves both enterprise and service providers alike somewhat on edge. How can service providers entice the enterprise? How do they prove their services are above and beyond the other thousand-or-so offerings out there? How does the enterprise go about choosing an IaaS partner (and have no doubts, enterprises want partners, not providers, when it comes to managing their data and applications)? How do they ensure the operational efficiency gained through their private cloud implementation isn’t lost by disjointed processes imposed by the differences in core application delivery services in public offerings? How do organizations avoid going into operational debt from managing two environments with two different sets of management and solutions? Architectural consistency is key to the answer, achieved through a fully cloud-enabled application delivery network. The F5 Cloud Licensing Program Whether the goal is scalability, security, better performance, availability, consolidation, or reducing costs, F5 enterprise customers have achieved these goals using F5 solutions. The next step is ensuring these same goals can be achieved in a public cloud, whether the implementation is pure public or hybrid cloud. To do that requires enabling cloud service providers with the ability to offer a complete application delivery network (ADN) in the cloud, with a cost structure appropriate to a utility service model. Given that 43% of respondents in a Cloud Computing Outlook 2011 survey indicated “lack of training” was inhibiting their cloud adoption, being able to offer such services that customers are familiar with is important. That’s the impetus behind the creation of the F5 Cloud Licensing Program, a new service-provider focused licensing model for the industry’s only complete cloud-enabled ADN. With services encompassing the entire application delivery chain – from security to acceleration to access control – this offering brings to the table the ability to maintain operational consistency from the data center into the cloud, without compromising on the infrastructure services needed by enterprises to take advantage of public cloud models. The Conspecific Hybrid Cloud Complexity Drives Consolidation Cloud Bursting: Gateway Drug for Hybrid Cloud Ecosystems are Always in Flux The Pythagorean Theorem of Operational Risk At the Intersection of Cloud and Control… Cloud Computing and the Truth About SLAs189Views0likes0CommentsCloud Bursting: Gateway Drug for Hybrid Cloud
The first hit’s cheap kid … Recently Ben Kepes started a very interesting discussion on cloud bursting by asking whether or not it was real. This led to Christofer Hoff pointing out that “true” cloud bursting required routing based on business parameters. That needs to be extended to operational parameters, but in general, Hoff’s on the mark in my opinion. The core of the issue with cloud bursting, however, is not that requests must be magically routed to the cloud in an overflow situation (that seems to be universally accepted as part of the definition), but the presumption that the content must also be dynamically pushed to the cloud as part of the process, i.e. live migration. If we accept that presumption then cloud bursting is nowhere near reality. Not because live migration can’t be done, but because the time requirement to do so prohibits a successful “just in time” bursting approach. There is already a requirement that provisioning of resources in the cloud as preparation for a bursting event happen well before the event, it’s a predictive, proactive process nor a reactionary one, and the inclusion of live migration as part of the process would likely result in false provisioning events (where content is migrated prematurely based on historical trending which fails to continue and therefore does not result in an overflow situation). So this leaves us with cloud bursting as a viable architectural solution to scale on-demand only if we pre-position content in the cloud, with the assumption that provisioning is a less time intensive process than migration plus provisioning. This results in a more permanent, hybrid cloud architecture. THE ROAD to HYBRID The constraints on the network today force organizations who wish to address their seasonal or periodic need for “overflow” capacity to pre-position the content in demand at a cloud provider. This isn’t as simple as dropping a virtual machine in EC2, it also requires DNS modifications to be made and the implementation of the policy that will ultimately trigger the routing to the cloud campus. Equally important – actually, perhaps more important – is having the process in place that will actually provision the application at the cloud campus. In other words, the organization is building out the foundation for a hybrid cloud architecture. But in terms of real usage, the cloud-deployed resources may only be used when overflow capacity is required. So it’s only used periodically. But as its user base grows, so does the need for that capacity and organizations will see those resources provisioned more and more often, until they’re virtually always on. There’s obviously an inflection point at which the use of cloud-based resources moves out of the realm of “overflow capacity” and into the realm of “capacity”, period. At that point, the organization is in possession of a full, hybrid cloud implementation. LIMITATIONS IMPOSE the MODEL Some might argue – and I’d almost certainly concede the point – that a cloud bursting model that requires pre-positioning in the first place is a hybrid cloud model and not the original intent of cloud bursting. The only substantive argument I could provide to counter is that cloud bursting focuses more on the use of the resources and not the model by which they are used. It’s the on-again off-again nature of the resources deployed at the cloud campus that make it cloud bursting, not the underlying model. Regardless, existing limitations on bandwidth force the organization’s hand; there’s virtually no way to avoid implementing what is a foundation for hybrid cloud as a means to execute on a cloud bursting strategy (which is probably a more accurate description of the concept than tying it to a technical implementation, but I’m getting off on a tangent now). The decision to embark on a cloud bursting initiative, therefore, should be made with the foresight that it requires essentially the same effort and investment as a hybrid cloud strategy. Recognizing that up front enables a broader set of options for using those cloud campus resources, particularly the ability to leverage them as true “utility” computing, rather than an application-specific (i.e. dedicated) set of resources. Because of the requirement to integrate and automate to achieve either model, organizations can architect both with an eye toward future integration needs – such as those surrounding identity management, which continues to balloon as a source of concern for those focusing in on SaaS and PaaS integration. Whether or not we’ll solve the issues with live migration as a barrier to “true” cloud bursting remains to be seen. As we’ve never managed to adequately solve the database replication issue (aside from accepting eventual consistency as reality), however, it seems likely that a “true” cloud bursting implementation may never be possible for organizations who aren’t mainlining the Internet backbone.281Views0likes0Comments