F5 Automated Backups - The Right Way
Hi all, Often I've been scouring the devcentral fora and codeshares to find that one piece of handywork that will drastically simplify my automated backup needs on F5 devices. Based on the works of Jason Rahm in his post "Third Time's the Charm: BIG-IP Backups Simplified with iCall" on the 26th of June 2013, I went ahead and created my own iApp that pretty much provides the answers for all my backup-needs. Here's a feature list of this iApp: It allows you to choose between both UCS or SCF as backup-types. (whilst providing ample warnings about SCF not being a very good restore-option due to the incompleteness in some cases) It allows you to provide a passphrase for the UCS archives (the standard GUI also does this, so the iApp should too) It allows you to not include the private keys (same thing: standard GUI does it, so the iApp does it too) It allows you to set a Backup Schedule for every X minutes/hours/days/weeks/months or a custom selection of days in the week It allows you to set the exact time, minute of the hour, day of the week or day of the month when the backup should be performed (depending on the usefulness with regards to the schedule type) It allows you to transfer the backup files to external devices using 4 different protocols, next to providing local storage on the device itself SCP (username/private key without password) SFTP (username/private key without password) FTP (username/password) SMB (using smbclient, with username/password) Local Storage (/var/local/ucs or /var/local/scf) It stores all passwords and private keys in a secure fashion: encrypted by the master key of the unit (f5mku), rendering it safe to store the backups, including the credentials off-box It has a configurable automatic pruning function for the Local Storage option, so the disk doesn't fill up (i.e. keep last X backup files) It allows you to configure the filename using the date/time wildcards from the tcl [clock] command, as well as providing a variable to include the hostname It requires only the WebGUI to establish the configuration you desire It allows you to disable the processes for automated backup, without you having to remove the Application Service or losing any previously entered settings For the external shellscripts it automatically generates, the credentials are stored in encrypted form (using the master key) It allows you to no longer be required to make modifications on the linux command line to get your automated backups running after an RMA or restore operation It cleans up after itself, which means there are no extraneous shellscripts or status files lingering around after the scripts execute I wasn't able to upload the iApp template to this article, so I threw it on pastebin: http://pastebin.com/YbDj3eMN Enjoy! Thomas Schockaert8.4KViews0likes79Comments
F5 Friday: Load Balancing MySQL with F5 BIG-IP
Scaling MySQL just got a whole lot easier load balancing MySQL – any database, really – is not a trivial task. Generally speaking one does not simply round robin your way through a cluster of MySQL databases as a means to achieve scalability. It is databases, in fact, that have driven a wide variety of scalability patterns such as sharding and partitioning to achieve the ultimate goal of high-performance and scalability simultaneously. Unfortunately, most folks don’t architect their applications with scalability in mind. A single database is all that’s necessary at first, and because of the way in which the application interacts with the database, it doesn’t make sense to code in support for multiple database instances, such as is often implemented with a MySQL master-slave cluster. That’s because the application has to actually open a connection to the database in question. If you’re only starting with one database, you really can’t code in a connection to a separate instance. Eventually that application’s usage grows and the demands upon the database require a more scalable approach. Enter the MySQL master/slave relationship. A typical configuration is to maintain the master as the “write” database, i.e. all updates and/or inserts must use the master, while the slave instance is used as a “read only” instance. Obviously this means the application code must be changed to support this kind of functional sharding. Unless you leverage network server virtualization from a load balancing service capable of acting as a full-proxy at layer 7 (application) like BIG-IP. This solution leverages iRules to implement database load balancing. While this specific example is designed to perform the common functional sharding pattern of read-write separation for a master-slave MySQL cluster, the flexibility of iRules is such that other architectural solutions can easily be designed using the same basic functions. Location based sharding is another popular means of scaling databases, and using the GeoLocation capabilities of BIG-IP along with iRules to inspect and route database requests, it should be a fairly trivial architectural task to implement. The ability to further extend sharding or other distribution methodologies for scaling databases without modifying the application itself is a huge bonus for both developers and operations. By decoupling the application from the database, it provides a more flexibility set of scalability domains in which technology targeted scalability strategies can be leveraged independent of the other layers. This is an important facet of agile infrastructure architecture and should not be underestimated as a benefit of network server virtualization. MySQL Load Balancing Resources: MySQL Proxy iRule MySQL Proxy iApp (deployment package for BIG-IP v11) The Full-Proxy Data Center Architecture Infrastructure Scalability Pattern: Sharding Streams Infrastructure Scalability Pattern: Sharding Sessions Infrastructure Scalability Pattern: Partition by Function or Type IT as a Service: A Stateless Infrastructure Architecture Model F5 Friday: Platform versus Product At the Intersection of Cloud and Control… What is a Strategic Point of Control Anyway? All F5 Friday Posts on DevCentral Why Single-Stack Infrastructure Sucks2.4KViews0likes0CommentsThe Challenges of SQL Load Balancing
#infosec #iam load balancing databases is fraught with many operational and business challenges. While cloud computing has brought to the forefront of our attention the ability to scale through duplication, i.e. horizontal scaling or “scale out” strategies, this strategy tends to run into challenges the deeper into the application architecture you go. Working well at the web and application tiers, a duplicative strategy tends to fall on its face when applied to the database tier. Concerns over consistency abound, with many simply choosing to throw out the concept of consistency and adopting instead an “eventually consistent” stance in which it is assumed that data in a distributed database system will eventually become consistent and cause minimal disruption to application and business processes. Some argue that eventual consistency is not “good enough” and cite additional concerns with respect to the failure of such strategies to adequately address failures. Thus there are a number of vendors, open source groups, and pundits who spend time attempting to address both components. The result is database load balancing solutions. For the most part such solutions are effective. They leverage master-slave deployments – typically used to address failure and which can automatically replicate data between instances (with varying levels of success when distributed across the Internet) – and attempt to intelligently distribute SQL-bound queries across two or more database systems. The most successful of these architectures is the read-write separation strategy, in which all SQL transactions deemed “read-only” are routed to one database while all “write” focused transactions are distributed to another. Such foundational separation allows for higher-layer architectures to be implemented, such as geographic based read distribution, in which read-only transactions are further distributed by geographically dispersed database instances, all of which act ultimately as “slaves” to the single, master database which processes all write-focused transactions. This results in an eventually consistent architecture, but one which manages to mitigate the disruptive aspects of eventually consistent architectures by ensuring the most important transactions – write operations – are, in fact, consistent. Even so, there are issues, particularly with respect to security. MEDIATION inside the APPLICATION TIERS Generally speaking mediating solutions are a good thing – when they’re external to the application infrastructure itself, i.e. the traditional three tiers of an application. The problem with mediation inside the application tiers, particularly at the data layer, is the same for infrastructure as it is for software solutions: credential management. See, databases maintain their own set of users, roles, and permissions. Even as applications have been able to move toward a more shared set of identity stores, databases have not. This is in part due to the nature of data security and the need for granular permission structures down to the cell, in some cases, and including transactional security that allows some to update, delete, or insert while others may be granted a different subset of permissions. But more difficult to overcome is the tight-coupling of identity to connection for databases. With web protocols like HTTP, identity is carried along at the protocol level. This means it can be transient across connections because it is often stuffed into an HTTP header via a cookie or stored server-side in a session – again, not tied to connection but to identifying information. At the database layer, identity is tightly-coupled to the connection. The connection itself carries along the credentials with which it was opened. This gives rise to problems for mediating solutions. Not just load balancers but software solutions such as ESB (enterprise service bus) and EII (enterprise information integration) styled solutions. Any device or software which attempts to aggregate database access for any purpose eventually runs into the same problem: credential management. This is particularly challenging for load balancing when applied to databases. LOAD BALANCING SQL To understand the challenges with load balancing SQL you need to remember that there are essentially two models of load balancing: transport and application layer. At the transport layer, i.e. TCP, connections are only temporarily managed by the load balancing device. The initial connection is “caught” by the Load balancer and a decision is made based on transport layer variables where it should be directed. Thereafter, for the most part, there is no interaction at the load balancer with the connection, other than to forward it on to the previously selected node. At the application layer the load balancing device terminates the connection and interacts with every exchange. This affords the load balancing device the opportunity to inspect the actual data or application layer protocol metadata in order to determine where the request should be sent. Load balancing SQL at the transport layer is less problematic than at the application layer, yet it is at the application layer that the most value is derived from database load balancing implementations. That’s because it is at the application layer where distribution based on “read” or “write” operations can be made. But to accomplish this requires that the SQL be inline, that is that the SQL being executed is actually included in the code and then executed via a connection to the database. If your application uses stored procedures, then this method will not work for you. It is important to note that many packaged enterprise applications rely upon stored procedures, and are thus not able to leverage load balancing as a scaling option. Depending on your app or how your organization has agreed to protect your data will determine which of these methods are used to access your databases. The use of inline SQL affords the developer greater freedom at the cost of security, increased programming(to prevent the inherent security risks), difficulty in optimizing data and indices to adapt to changes in volume of data, and deployment burdens. However there is lively debate on the values of both access methods and how to overcome the inherent risks. The OWASP group has identified the injection attacks as the easiest exploitation with the most damaging impact. This also requires that the load balancing service parse MySQL or T-SQL (the Microsoft Transact Structured Query Language). Databases, of course, are designed to parse these string-based commands and are optimized to do so. Load balancing services are generally not designed to parse these languages and depending on the implementation of their underlying parsing capabilities, may actually incur significant performance penalties to do so. Regardless of those issues, still there are an increasing number of organizations who view SQL load balancing as a means to achieve a more scalable data tier. Which brings us back to the challenge of managing credentials. MANAGING CREDENTIALS Many solutions attempt to address the issue of credential management by simply duplicating credentials locally; that is, they create a local identity store that can be used to authenticate requests against the database. Ostensibly the credentials match those in the database (or identity store used by the database such as can be configured for MSSQL) and are kept in sync. This obviously poses an operational challenge similar to that of any distributed system: synchronization and replication. Such processes are not easily (if at all) automated, and rarely is the same level of security and permissions available on the local identity store as are available in the database. What you generally end up with is a very loose “allow/deny” set of permissions on the load balancing device that actually open the door for exploitation as well as caching of credentials that can lead to unauthorized access to the data source. This also leads to potential security risks from attempting to apply some of the same optimization techniques to SQL connections as is offered by application delivery solutions for TCP connections. For example, TCP multiplexing (sharing connections) is a common means of reusing web and application server connections to reduce latency (by eliminating the overhead associated with opening and closing TCP connections). Similar techniques at the database layer have been used by application servers for many years; connection pooling is not uncommon and is essentially duplicated at the application delivery tier through features like SQL multiplexing. Both connection pooling and SQL multiplexing incur security risks, as shared connections require shared credentials. So either every access to the database uses the same credentials (a significant negative when considering the loss of an audit trail) or we return to managing duplicate sets of credentials – one set at the application delivery tier and another at the database, which as noted earlier incurs additional management and security risks. YOU CAN’T WIN FOR LOSING Ultimately the decision to load balance SQL must be a combination of business and operational requirements. Many organizations successfully leverage load balancing of SQL as a means to achieve very high scale. Generally speaking the resulting solutions – such as those often touted by e-Bay - are based on sound architectural principles such as sharding and are designed as a strategic solution, not a tactical response to operational failures and they rarely involve inspection of inline SQL commands. Rather they are based on the ability to discern which database should be accessed given the function being invoked or type of data being accessed and then use a traditional database connection to connect to the appropriate database. This does not preclude the use of application delivery solutions as part of such an architecture, but rather indicates a need to collaborate across the various application delivery and infrastructure tiers to determine a strategy most likely to maintain high-availability, scalability, and security across the entire architecture. Load balancing SQL can be an effective means of addressing database scalability, but it should be approached with an eye toward its potential impact on security and operational management. What are the pros and cons to keeping SQL in Stored Procs versus Code Mission Impossible: Stateful Cloud Failover Infrastructure Scalability Pattern: Sharding Streams The Real News is Not that Facebook Serves Up 1 Trillion Pages a Month… SQL injection – past, present and future True DDoS Stories: SSL Connection Flood Why Layer 7 Load Balancing Doesn’t Suck Web App Performance: Think 1990s.2.1KViews0likes1CommentWhat is a Strategic Point of Control Anyway?
From mammoth hunting to military maneuvers to the datacenter, the key to success is control Recalling your elementary school lessons, you’ll probably remember that mammoths were large and dangerous creatures and like most animals they were quite deadly to primitive man. But yet man found a way to hunt them effectively and, we assume, with more than a small degree of success as we are still here and, well, the mammoths aren’t. Marx Cavemen PHOTO AND ART WORK : Fred R Hinojosa. The theory of how man successfully hunted ginormous creatures like the mammoth goes something like this: a group of hunters would single out a mammoth and herd it toward a point at which the hunters would have an advantage – a narrow mountain pass, a clearing enclosed by large rock, etc… The qualifying criteria for the place in which the hunters would finally confront their next meal was that it afforded the hunters a strategic point of control over the mammoth’s movement. The mammoth could not move away without either (a) climbing sheer rock walls or (b) being attacked by the hunters. By forcing mammoths into a confined space, the hunters controlled the environment and the mammoth’s ability to flee, thus a successful hunt was had by all. At least by all the hunters; the mammoths probably didn’t find it successful at all. Whether you consider mammoth hunting or military maneuvers or strategy-based games (chess, checkers) one thing remains the same: a winning strategy almost always involves forcing the opposition into a situation over which you have control. That might be a mountain pass, or a densely wooded forest, or a bridge. The key is to force the entire complement of the opposition through an easily and tightly controlled path. Once they’re on that path – and can’t turn back – you can execute your plan of attack. These easily and highly constrained paths are “strategic points of control.” They are strategic because they are the points at which you are empowered to perform some action with a high degree of assurance of success. In data center architecture there are several “strategic points of control” at which security, optimization, and acceleration policies can be applied to inbound and outbound data. These strategic points of control are important to recognize as they are the most efficient – and effective – points at which control can be exerted over the use of data center resources. DATA CENTER STRATEGIC POINTS of CONTROL In every data center architecture there are aggregation points. These are points (one or more components) through which all traffic is forced to flow, for one reason or another. For example, the most obvious strategic point of control within a data center is at its perimeter – the router and firewalls that control inbound access to resources and in some cases control outbound access as well. All data flows through this strategic point of control and because it’s at the perimeter of the data center it makes sense to implement broad resource access policies at this point. Similarly, strategic points of control occur internal to the data center at several “tiers” within the architecture. Several of these tiers are: Storage virtualization provides a unified view of storage resources by virtualizing storage solutions (NAS, SAN, etc…). Because the storage virtualization tier manages all access to the resources it is managing, it is a strategic point of control at which optimization and security policies can be easily applied. Application Delivery / load balancing virtualizes application instances and ensures availability and scalability of an application. Because it is virtualizing the application it therefore becomes a point of aggregation through which all requests and responses for an application must flow. It is a strategic point of control for application security, optimization, and acceleration. Network virtualization is emerging internal to the data center architecture as a means to provide inter-virtual machine connectivity more efficiently than perhaps can be achieved through traditional network connectivity. Virtual switches often reside on a server on which multiple applications have been deployed within virtual machines. Traditionally it might be necessary for communication between those applications to physically exit and re-enter the server’s network card. But by virtualizing the network at this tier the physical traversal path is eliminated (and the associated latency, by the way) and more efficient inter-vm communication can be achieved. This is a strategic point of control at which access to applications at the network layer should be applied, especially in a public cloud environment where inter-organizational residency on the same physical machine is highly likely. OLD SKOOL VIRTUALIZATION EVOLVES You might have begun noticing a central theme to these strategic points of control: they are all points at which some kind of virtualization – and thus aggregation – occur naturally in a data center architecture. This is the original (first) kind of virtualization: the presentation of many resources as a single resources, a la load balancing and other proxy-based solutions. When there is a one —> many (1:M) virtualization solution employed, it naturally becomes a strategic point of control by virtue of the fact that all “X” traffic must flow through that solution and thus policies regarding access, security, logging, etc… can be applied in a single, centrally managed location. The key here is “strategic” and “control”. The former relates to the ability to apply the latter over data at a single point in the data path. This kind of 1:M virtualization has been a part of datacenter architectures since the mid 1990s. It’s evolved to provide ever broader and deeper control over the data that must traverse these points of control by nature of network design. These points have become, over time, strategic in terms of the ability to consistently apply policies to data in as operationally efficient manner as possible. Thus have these virtualization layers become “strategic points of control”. And you thought the term was just another square on the buzz-word bingo card, didn’t you?1.1KViews0likes6Comments
F5 Predicts: Education gets personal
The topic of education is taking centre stage today like never before. I think we can all agree that education has come a long way from the days where students and teachers were confined to a classroom with a chalkboard. Technology now underpins virtually every sector and education is no exception. The Internet is now the principal enabling mechanism by which students assemble, spread ideas and sow economic opportunities. Education data has become a hot topic in a quest to transform the manner in which students learn. According to Steven Ross, a professor at the Centre for Research and Reform in Education at Johns Hopkins University, the use of data to customise education for students will be the key driver for learning in the future[1].This technological revolution has resulted in a surge of online learning courses accessible to anyone with a smart device. A two-year assessment of the massive open online courses (MOOCs) created by HarvardX and MITxrevealed that there were 1.7 million course entries in the 68 MOOC [2].This translates to about 1 million unique participants, who on average engage with 1.7 courses each. This equity of education is undoubtedly providing vast opportunities for students around the globe and improving their access to education. With more than half a million apps to choose from on different platforms such as the iOS and Android, both teachers and students can obtain digital resources on any subject. As education progresses in the digital era, here are some considerations for educational institutions to consider: Scale and security The emergence of a smogasborad of MOOC providers, such as Coursera and edX, have challenged the traditional, geographical and technological boundaries of education today. Digital learning will continue to grow driving the demand for seamless and user friendly learning environments. In addition, technological advancements in education offers new opportunities for government and enterprises. It will be most effective if provided these organisations have the ability to rapidly scale and adapt to an all new digital world – having information services easily available, accessible and secured. Many educational institutions have just as many users as those in large multinational corporations and are faced with the issue of scale when delivering applications. The aim now is no longer about how to get fast connection for students, but how quickly content can be provisioned and served and how seamless the user experience can be. No longer can traditional methods provide our customers with the horizontal scaling needed. They require an intelligent and flexible framework to deploy and manage applications and resources. Hence, having an application-centric infrastructure in place to accelerate the roll-out of curriculum to its user base, is critical in addition to securing user access and traffic in the overall environment. Ensuring connectivity We live in a Gen-Y world that demands a high level of convenience and speed from practically everyone and anything. This demand for convenience has brought about reform and revolutionised the way education is delivered to students. Furthermore, the Internet of things (IoT), has introduced a whole new raft of ways in which teachers can educate their students. Whether teaching and learning is via connected devices such as a Smart Board or iPad, seamless access to data and content have never been more pertinent than now. With the increasing reliance on Internet bandwidth, textbooks are no longer the primary means of educating, given that students are becoming more web oriented. The shift helps educational institutes to better personalise the curriculum based on data garnered from students and their work. Duty of care As the cloud continues to test and transform the realms of education around the world, educational institutions are opting for a centralised services model, where they can easily select the services they want delivered to students to enhance their learning experience. Hence, educational institutions have a duty of care around the type of content accessed and how it is obtained by students. They can enforce acceptable use policies by only delivering content that is useful to the curriculum, with strong user identification and access policies in place. By securing the app, malware and viruses can be mitigated from the institute’s environment. From an outbound perspective, educators can be assured that students are only getting the content they are meant to get access to. F5 has the answer BIG-IP LTM acts as the bedrock for educational organisations to provision, optimise and deliver its services. It provides the ability to publish applications out to the Internet in a quickly and timely manner within a controlled and secured environment. F5 crucially provides both the performance and the horizontal scaling required to meet the highest levels of throughput. At the same time, BIG-IP APM provides schools with the ability to leverage virtual desktop infrastructure (VDI) applications downstream, scale up and down and not have to install costly VDI gateways on site, whilst centralising the security decisions that come with it. As part of this, custom iApps can be developed to rapidly and consistently deliver, as well as reconfigure the applications that are published out to the Internet in a secure, seamless and manageable way. BIG-IP Application Security Manager (ASM) provides an application layer security to protect vital educational assets, as well as the applications and content being continuously published. ASM allows educational institutes to tailor security profiles that fit like a glove to wrap seamlessly around every application. It also gives a level of assurance that all applications are delivered in a secure manner. Education tomorrow It is hard not to feel the profound impact that technology has on education. Technology in the digital era has created a new level of personalised learning. The time is ripe for the digitisation of education, but the integrity of the process demands the presence of technology being at the forefront, so as to ensure the security, scalability and delivery of content and data. The equity of education that technology offers, helps with addressing factors such as access to education, language, affordability, distance, and equality. Furthermore, it eliminates geographical boundaries by enabling the mass delivery of quality education with the right policies in place. [1] http://www.wsj.com/articles/SB10001424052702304756104579451241225610478 [2] http://papers.ssrn.com/sol3/papers.cfm?abstract_id=2586847843Views0likes3CommentsSessions, Sessions Everywhere
If you’re replicating session state across application servers you probably need to rethink your strategy. There’s other options – more efficient options – than wasting RAM and, ultimately, money. Although the discussion of Oracle’s “cloud in a box” announcement at OpenWorld dominated much of the tweet-stream this week there were other discussions going on that proved to not only interesting but a good reminder of how cloud computing has brought to the fore the importance of architecture. Foremost in my mind was what started as a lamentation on the fact that Amazon EC2 does not support multicasting that evolved into a discussion on why that would cause grief for those deploying applications in the environment. Remember that multicast is essentially spraying the same data to a group of endpoints and is usually leveraged for streaming media topologies: In computer networking, multicast is the delivery of a message or information to a group of destination computers simultaneously in a single transmission from the source creating copies automatically in other network elements, such as routers, only when the topology of the network requires it. -- Wikipedia, multicast As it turns out, a primary reason behind the need for multicasting in the application architecture revolves around the mirroring of session state across a pool of application servers. Yeah, you heard that right – mirroring session state across a pool of application servers. The first question has to be: why? What is it about an application that requires this level of duplication? MULTICASTING for SESSIONS There are three reasons why someone would want to use multicasting to mirror session state across a pool of application servers. There may be additional reasons that aren’t as common and if so, feel free to share. The application relies on session state and, when deployed in a load balanced environment, broke because the tight-coupling between user and session state was not respected by the Load balancer. This is a common problem when moving from dev/qa to production and is generally caused by using a load balancing algorithm without enabling persistence, a.k.a. sticky sessions. The application requires high-availability that necessitates architecting a stateful-failover architecture. By mirroring sessions to all application servers if one fails (or is decommissioned in an elastic environment) another can easily re-establish the coupling between the user and their session. This is not peculiar to application architecture – load balancers and application delivery controllers mirror their own “session” state across redundant pairs to achieve a stateful failover architecture as well. Some applications, particularly those that are collaborative in nature (think white-boarding and online conferences) “spray” data across a number of sessions in order to enable the sharing in real time aspect of the application. There are other architectural choices that can achieve this functionality, but there are tradeoffs to all of them and in this case it is simply one of several options. THE COST of REPLICATING SESSIONS With the exception of addressing the needs of collaborative applications (and even then there are better options from an architectural point of view) there are much more efficient ways to handle the tight-coupling of user and session state in an elastic or scaled-out environment. The arguments against multicasting session state are primarily around resource consumption, which is particularly important in a cloud computing environment. Consider that the typical session state is 3-200 KB in size (Session State: Beyond Soft State ). Remember that if you’re mirroring every session across an entire cluster (pool) of application servers, that each server must use memory to store that session. Each mirrored session, then, is going to consume resources on every application server. Every application server has, of course, a limited amount of memory it can utilize. It needs that memory for more than just storing session state – it must also store connection tables, its own configuration data, and of course it needs memory in which to execute application logic. If you consume a lot of the available memory storing the session state from every other application server, you are necessarily reducing the amount of memory available to perform other important tasks. This reduces the capacity of the server in terms of users and connections, it reduces the speed with which it can execute application logic (which translates into reduced response times for users), and it operates on a diminishing returns principle. The more application servers you need to scale – and you’ll need more, more frequently, using this technique – the less efficient each added application server becomes because a good portion of its memory is required simply to maintain session state of all the other servers in the pool. It is exceedingly inefficient and, when leveraging a public cloud computing environment, more expensive. It’s a very good example of the diseconomy of scale associated with traditional architectures – it results in a “throw more ‘hardware’ at the problem, faster” approach to scalability. BETTER ARCHITECTURAL SOLUTIONS There are better architectural solutions to maintaining session state for every user. SHARED DATABASE Storing session state in a shared database is a much more efficient means of mirroring session state and allows for the same guarantees of consistency when experiencing a failure. If session state is stored in a database then regardless of which application server instance a user is directed to that application server has access to its session state. The interaction between the user and application becomes: User sends request Clustering/load balancing solution routes to application server Application server receives request, looks up session in database Application server processes request, creates response Application server stores updated session in database Application server returns response If a single database is problematic (because it is a single point of failure) then multicasting or other replication techniques can be used to implement a dual-database architecture. This is somewhat inefficient, but far less so than doing the same at the application server layer. PERSISTENCE-BASED LOAD BALANCING It is often the case that the replication of session state is implemented in response to wonky application behavior occurring only when the application is deployed in a scalable environment, a.k.a a load balancing solution is introduced into the architecture. This is almost always because the application requires tight-coupling between user and session and the load balancing is incorrectly configured to support this requirement. Almost every load balancing solution – hardware, software, virtual network appliance, infrastructure service – is capable of supporting persistence, a.k.a. sticky sessions. This solution requires, however, that the load balancing solution of choice be configured to support the persistence. Persistence (also sometimes referred to as “server affinity” when implemented by a clustering solution) can be configured in a number of ways. The most common configuration is to leverage the automated session IDs generated by application servers, e.g. PHPSESSIONID, ASPSESSIONID. These ids are contained in the HTTP headers and are, as a matter of fact, how the application server “finds” the appropriate session for any given user’s request. The load balancer intercepts every request (it does anyway) and performs the same type of lookup on its own session table (which is much, much higher capacity than an application server and leverages the same high-performance lookups used to store connection and network session tables) and routes the user to the appropriate application server based on the session ID. The interaction between the user and application becomes: User sends request Clustering/load balancing solution finds, if existing, the session-app server mapping. If it does not, it chooses the application server based on the load balancing algorithm and configured parameters Application server receives request, Application server processes request, creates response Application server returns response Clustering/load balancing solution creates the session-app server mapping if it did not already exist Persistence can generally be based on any data in the HTTP header or payload, but using the automatically generated session ids tends to be the most common implementation. YOUR INFRASTRUCTURE, GIVE IT TO ME Now, it may be the case when the multicasting architecture is the right one. It is impossible to say it’s never the right solution because there are always applications and specific scenarios in which an architecture that may not be a good idea in general is, in fact, the right solution. It is likely the case, however, in most situations that it is not the right solution and has more than likely been implemented as a workaround in response to problems with application behavior when moving through a staged development environment. This is one of the best reasons why the use of a virtual edition of your production load balancing solution should be encouraged in development environments. The earlier a holistic strategy to application design and architecture can be employed the fewer complications will be experienced when the application moves into the production environment. Leveraging a virtual version of your load balancing solution during the early stages of the development lifecycle can also enable developers to become familiar with production-level infrastructure services such that they can employ a holistic, architectural approach to solving application issues. See, it’s not always because developers don’t have the know how, it’s because they don’t have access to the tools during development and therefore can’t architect a complete solution. I recall a developer’s plaintive query after a keynote at [the now defunct] SD West conference a few years ago that clearly indicated a reluctance to even ask the network team for access to their load balancing solution to learn how to leverage its services in application development because he knew he would likely be denied. Network and application delivery network pros should encourage the use of and tinkering with virtual versions of application delivery controllers/load balancers in the application development environment as much as possible if they want to reduce infrastructure and application architectural-related issues from cropping up during production deployment. A greater understanding of application-infrastructure interaction will enable more efficient, higher performing applications in general and reduce the operational expenses associated with deploying applications that use inefficient methods such as replication of session state to address application architectural constraints. Related blogs & articles: Applying Scalability Patterns to Infrastructure Architecture Scalability Only One Half the Reliability Equation Service Virtualization Helps Localize Impact of Elastic Scalability Web 2.0: Integration, APIs, and Scalability Automating scalability and high availability services To Take Advantage of Cloud Computing You Must Unlearn, Luke. Scalability with multiple networks for Virtual Servers ... Cloud Lets You Throw More Hardware at the Problem Faster And That, Young Cloudwalker, Is Why You Fail577Views0likes0CommentsBuilding an elastic environment requires elastic infrastructure
One of the reasons behind some folks pushing for infrastructure as virtual appliances is the on-demand nature of a virtualized environment. When network and application delivery infrastructure hits capacity in terms of throughput - regardless of the layer of the application stack at which it happens - it's frustrating to think you might need to upgrade the hardware rather than just add more compute power via a virtual image. The truth is that this makes sense. The infrastructure supporting a virtualized environment should be elastic. It should be able to dynamically expand without requiring a new network architecture, a higher performing platform, or new configuration. You should be able to just add more compute resources and walk away. The good news is that this is possible today. It just requires that you consider carefully your choices in network and application network infrastructure when you build out your virtualized infrastructure. ELASTIC APPLICATION DELIVERY INFRASTRUCTURE Last year F5 introduced VIPRION, an elastic, dynamic application networking delivery platform capable of expanding capacity without requiring any changes to the infrastructure. VIPRION is a chassis-based bladed application delivery controller and its bladed system behaves much in the same way that a virtualized equivalent would behave. Say you start with one blade in the system, and soon after you discover you need more throughput and more processing power. Rather than bring online a new virtual image of such an appliance to increase capacity, you add a blade to the system and voila! VIPRION immediately recognizes the blade and simply adds it to its pools of processing power and capacity. There's no need to reconfigure anything, VIPRION essentially treats each blade like a virtual image and distributes requests and traffic across the network and application delivery capacity available on the blade automatically. Just like a virtual appliance model would, but without concern for the reliability and security of the platform. Traditional application delivery controllers can also be scaled out horizontally to provide similar functionality and behavior. By deploying additional application delivery controllers in what is often called an active-active model, you can rapidly deploy and synchronize configuration of the master system to add more throughput and capacity. Meshed deployments comprising more than a pair of application delivery controllers can also provide additional network compute resources beyond what is offered by a single system. The latter option (the traditional scaling model) requires more work to deploy than the former (VIPRION) simply because it requires additional hardware and all the overhead required of such a solution. The elastic option with bladed, chassis-based hardware is really the best option in terms of elasticity and the ability to grow on-demand as your infrastructure needs increase over time. ELASTIC STORAGE INFRASTRUCTURE Often overlooked in the network diagrams detailing virtualized infrastructures is the storage layer. The increase in storage needs in a virtualized environment can be overwhelming, as there is a need to standardize the storage access layer such that virtual images of applications can be deployed in a common, unified way regardless of which server they might need to be executing on at any given time. This means a shared, unified storage layer on which to store images that are necessarily large. This unified storage layer must also be expandable. As the number of applications and associated images are made available, storage needs increase. What's needed is a system in which additional storage can be added in a non-disruptive manner. If you have to modify the automation and orchestration systems driving your virtualized environment when additional storage is added, you've lost some of the benefits of a virtualized storage infrastructure. F5's ARX series of storage virtualization provides that layer of unified storage infrastructure. By normalizing the namespaces through which files (images) are accessed, the systems driving a virtualized environment can be assured that images are available via the same access method regardless of where the file or image is physically located. Virtualized storage infrastructure systems are dynamic; additional storage can be added to the infrastructure and "plugged in" to the global namespace to increase the storage available in a non-disruptive manner. An intelligent virtualized storage infrastructure can further make more efficient the use of the storage available by tiering the storage. Images and files accessed more frequently can be stored on fast, tier one storage so they are loaded and execute more quickly, while less frequently accessed files and images can be moved to less expensive and perhaps less peformant storage systems. By deploying elastic application delivery network infrastructure instead of virtual appliances you maintain stability, reliability, security, and performance across your virtualized environment. Elastic application delivery network infrastructure is already dynamic, and offers a variety of options for integration into automation and orchestration systems via standards-based control planes, many of which are nearly turn-key solutions. The reasons why some folks might desire a virtual appliance model for their application delivery network infrastructure are valid. But the reality is that the elasticity and on-demand capacity offered by a virtual appliance is already available in proven, reliable hardware solutions today that do not require sacrificing performance, security, or flexibility. Related articles by Zemanta How to instrument your Java EE applications for a virtualized environment Storage Virtualization Fundamentals Automating scalability and high availability services Building a Cloudbursting Capable Infrastructure EMC unveils Atmos cloud offering Are you (and your infrastructure) ready for virtualization?502Views0likes4Comments
Cloud Storage Gateways. Short term win, but long term…?
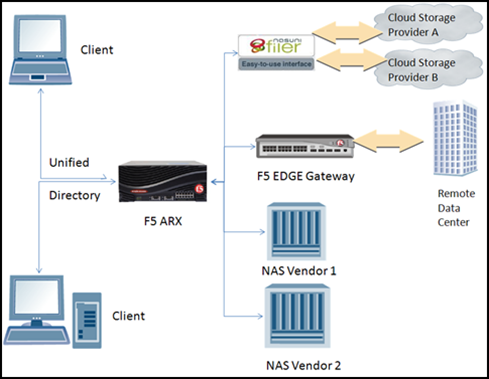
In the rush to cloud, there are many tools and technologies out there that are brand new. I’ve covered a few, but that’s nowhere near a complete list, but it’s interesting to see what is going on out there from a broad-spectrum view. I have talked a bit about Cloud Storage Gateways here. And I’m slowly becoming a fan of this technology for those who are considering storing in the cloud tier. There are a couple of good reasons to consider these products, and I was thinking about the reasons and their standing validity. Thought I’d share with you where I stand on them at this time, and what I see happening that might impact their value proposition. The two vendors I have taken some time to research while preparing this blog for you are Nasuni and Panzura. No doubt there are plenty of others, but I’m writing you a blog here, not researching a major IT initiative. So I researched two of them to have some points of comparison, and leave the in-depth vendor selection research to you and your staff. These two vendors present similar base technology and very different additional feature sets. Both rely heavily upon local caching in the controller box, and both work with multiple cloud vendors, and both claim to manage compression. Nasuni delivers as a Virtual Appliance, includes encryption on your network before transmitting to the cloud, automated cloud provisioning, and caching that has timed updates to the cloud, but can perform a forced update if the cache gets full. It presents the cloud storage you’ve provisioned as a NAS on your end. Panzura delivers a hardware appliance that also presents the cloud as a NAS, works with multiple cloud vendors, handles encryption on-device, and claims global dedupe. I say claims, because “global” has a meaning that is “all” and in their case “all” means “all the storage we know about”, not “all the storage you know”. I would prefer a different term, but I get what they mean. Like everything else, they can’t de-dupe what they don’t control. They too present the cloud storage you’ve provisioned as a NAS on your end, but claim to accelerate CIFS and NFS also. Panzura is also trying to make a big splash about speeding access to MS-Sharepoint, but honestly, as a TMM for F5, a company that makes two astounding products that speed access to Sharepoint and nearly everything else on the Internet (LTM and WOM), I’m not impressed by Sharepoint acceleration. In fact, our Sharepoint Application Ready Solution is here, and our list of Application Ready Solutions is here. Those are just complete architectures we support directly, and don’t touch on what you can do with the products through Virtuals, iRules, profiles, and the host of other dials and knobs. I could go on and on about this topic, but that’s not the point of this blog, so suffice it to say there are some excellent application acceleration and WAN Optimization products out there, so this point solution alone should not be a buying criteria. There are some compelling reasons to purchase one of these products if you are considering cloud storage as a possible solution. Let’s take a look at them. Present cloud storage as a NAS – This is a huge benefit right now, but over time the importance will hopefully decrease as standards for cloud storage access emerge. Even if there is no actual standard that everyone agrees to, it will behoove smaller players to emulate the larger players that are allowing access to their storage in a manner that is similar to other storage technologies. Encryption – As far as I can see this will always be a big driver. They’re taking care of encryption for you, so you can sleep at night as they ship your files to the public cloud. If you’re considering them for non-public cloud, this point may still be huge if your pipe to the storage is over the public Internet. Local Caching – With current broadband bandwidths, this will be a large driver for the foreseeable future. You need your storage to be responsive, and local caching increases responsiveness, depending upon implementation, cache size, and how many writes you are doing this could be a huge improvement. De-duplication – I wish I had more time to dig into what these vendors mean by dedupe. Replacing duplicate files with a symlink is simplest and most resembles existing file systems, but it is also significantly less effective than partial file de-dupe. Let’s face it, most organizations have a lot more duplication laying around in files named Filename.Draft1.doc through Filename.DraftX.doc than they do in completely duplicate files. Check with the vendors if you’re considering this technology to find out what you can hope to gain from their de-dupe. This is important for the simple reason that in the cloud, you pay for what you use. That makes de-duplication more important than it has historically been. The largest caution sign I can see is vendor viability. This is a new space, and we have plenty of history with early entry players in a new space. Some will fold, some will get bought up by companies in adjacent spaces, some will be successful… at something other than Cloud Storage Gateways, and some will still be around in five or ten years. Since these products compress, encrypt, and de-dupe your data, and both of them manage your relationship with the cloud vendor, losing them is a huge risk. I would advise some due diligence before signing on with one – new companies in new market spaces are not always a risky proposition, but you’ll have to explore the possibilities to make sure your company is protected. After all, if they’re as good as they seem, you’ll soon have more data running through them than you’ll have free space in your data center, making eliminating them difficult at best. I haven’t done the research to say which product I prefer, and my gut reaction may well be wrong, so I’ll leave it to you to check into them if the topic interests you. They would certainly fit well with an ARX, as I mentioned in that other blog post. Here’s a sample architecture that would make “the Cloud Tier” just another piece of your virtual storage directory under ARX, complete with automated tiering and replication capabilities that ARX owners thrive on. This sample architecture shows your storage going to a remote data center over EDGE Gateway, to the cloud over Nasuni, and to NAS boxes, all run through an ARX to make the client (which could be a server or a user – remember this is the NAS client) see a super-simplified, unified directory view of the entire thing. Note that this is theoretical, to my knowledge no testing has occurred between Nasuni and ARX, and usually (though certainly not always) the storage traffic sent over EDGE Gateway will be from a local NAS to a remote one, but there is no reason I can think of for this not to work as expected – as long as the Cloud Gateway really presents itself as a NAS. That gives you several paths to replicate your data, and still presents client machines with a clean, single-directory NAS that participates in ADS if required. In this case Tier one could be NAS Vendor 1, Tier two NAS Vendor 2, your replication targets securely connected over EDGE Gateway, and tier 3 (things you want to save but no longer need to replicate for example) is the cloud as presented by the Cloud Gateway. The Cloud Gateway would arbitrate between actual file systems and whatever idiotic interface the cloud provider decided to present and tell you to deal with, while the ARX presents all of these different sources as a single-directory-tree NAS to the clients, handling tiering between them, access control, etc. And yes, if you’re not an F5 shop, you could indeed accomplish pieces of this architecture with other solutions. Of course, I’m biased, but I’m pretty certain the solution would not be nearly as efficient, cool, or let you sleep as well at night. Storage is complicated, but this architecture cleans it up a bit. And that’s got to be good for you. And all things considered, the only issue that is truly concerning is failure of a startup cloud gateway vendor. If another vendor takes one over, they’ll either support it or provide a migration path, if they are successful at something else, you’ll have plenty of time to move off of their storage gateway product, so only outright failure is a major concern. Related Articles and Blogs Panzura Launches ANS, Cloud Storage Enabled Alternative to NAS Nasuni Cloud Storage Gateway InfoSmack Podcasts #52: Nasuni (Podcast) F5’s BIG-IP Edge Gateway Solution Takes New Approach to Unifying, Optimizing Data Center Access Tiering is Like Tables or Storing in the Cloud Tier443Views0likes1Comment
Learning EMC server stats for statistic collection
Once upon a time, not too long ago, the EMC's command line interface utilized a few known commands for gathering statistics. The commands I grew used to were called server_cifsstat and server_nfsstat but then one day when I called upon their mighty powers they responded to me with an unexpected echo: Info 26306752352: server_2 : This command has been deprecated and replaced with server_stats command. "Deprecated!?", I yelled into the air, fists raised high as if I was clutching doom! I slowly put my hands down, took a deep breath and started to focus my inner child towards more positive thoughts. Years of software development and design decisions played through my head as I realized, "there must be a new way of doing the old thing." I just had to search for an answer, much as my old friend Indiana Jones would do, I went into the deep dark caverns of documentation to solve the riddle. Okay, I'm really not that great at reading documentation but once I found a command called server_stats (keyword "stats" gave it away to me) I realized I was heading down the right path… but I was still lost in the darkness. When I executed the command I received a cryptic message: [nasadmin@EMC-VNX-SIM ~]$ server_stats USAGE: server_stats -list | -info [-all|[,...]] | -service { -start [-port ] | -stop | -delete | -status } | -monitor -action {status|enable|disable} |[ [{ -monitor {statpath_name|statgroup_name}[,...] | -monitor {statpath_name|statgroup_name} [-sort ] [-order {asc|desc}] [-lines ] }...] [-count ] [-interval ] [-terminationsummary {no|yes|only}] [-format {text [-titles {never|once|}]|csv}] [-type {rate|diff|accu}] [-file [-overwrite]] The command, which was pretty easy before, has turned into something a bit harder for me to wield but, thanks to some research, experimentation and friends here I can count on, we formulated a single-line statistics gathering command that would do what we needed. I emphasis friends that I can count on, because we have some pretty brilliant folks here. This is the magic sauce (all one one line): server_stats server_2 -monitor cifs.smb1,cifs.smb2,nfs.v2,nfs.v3,nfs.v4,cifs.global,nfs.basic -format csv -terminationsummary no -count 144 -interval 300 -type accu -file name-server_2.csv This command will capture statistics for CIFS/SMB version 1 and 2 as well as NFS version 2, 3 and 4 along with a few more statistics that we may want in the future (bandwidth, other stats and goodies, etc.) It will capture 144 statistical snapshots in time, every 300 seconds, and save them into name-server_2.csv (a comma-separated file with a nice header). One piece of the puzzle, that took me by surprise, was the -type accu option, which accumulates statistics upon each capture rather than starting back at a baseline of zero. You can also do 'diff' to capture the difference from interval to interval, which is nice… but unfortunately I am not able to utilize that feature. We have written tools to scan statistics on some storage devices like EMC and Network Appliance and, while this new command is super awesome, it's not consistent with anything else out there (even older releases prior to deprecation) so our in-house tools which calculate differences do the work for us. If you're looking to start working with the newerserver_stats feature, I suggest using the online manual pages (man server_stats) to get a slightly more clear understanding of all the features and what they can do for you. I believe the command is a bit large for what it needs to do for us, considering it deprecated a much simpler series of commands. However, we work with what we have and hopefully our example command line implementation will give you an understanding of how you can unlock the potential of server_stats for your own needs.435Views0likes1Comment
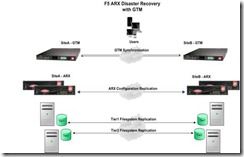
F5 ARX Disaster Recovery with BIG-IP Global Traffic Manager (GTM)
Introduction This article highlights the F5 ARX Disaster Recovery process via the configuration-replication feature (DMOS 5.2 and above) and Big-IP (v10.2.1) Global Traffic Manager (GTM). A new ARX global-config mode option enables as well as facilitates simple Disaster Recovery fail-over of all or part of a file virtualization environment from one ARX cluster to another assuming that files are being replicated using file server replication technology (i.e SnapMirror; VNX Replication; etc…). When an administrator wishes to fail-over to the other ARX cluster, they can load and enable all (or parts of) the replicated and shared global-config. This is important to note as the administrator has the ability to fail-over the entire site or down to a single Virtual IP (VIP) if needed. Having the ability and granularity of virtual server fail-over allows Active/Active configurations where some VIPs are active on SiteA and others are active on SiteB. In parallel, GTM pools can be configured and synchronized with ARX global-servers in order to fail-over to a DR data center. This ARX/GTM solution facilitates minimal end-user traffic disruption and/or down-time and a complete enterprise Disaster Recovery strategy, which minimizes Recovery Time and respective Recovery Point objectives. Problem/Challenge Prior to ARX DMOS 5.02.000, two-site Disaster Recovery solutions with storage based replication required manual scripts to keep ARX configurations in sync. These were Expect and Perl scripts used within production environments to perform ARX Disaster Recovery from one data center to another. Due to the complex nature of coordinating DR services across multiple devices, having to manually run additional scripts on ARX made the DR fail-over process more time consuming. Continual ARX CLI changes among all the various releases resulted in tedious script updates in order to accommodate CLI deltas among releases. With respect to DNS changes, once failed over to the DR site, administrators would need to manually change the ARX virtual-server IPs in the local DNS. In some instances, customers can have hundreds of virtual servers that would require manual local DNS changes before enabling the fail-over data center. Again, this proved tedious. Solution The ARX DMOS 5.2 configuration-replication feature accomplishes simple failover by configuring a global-config replication between ARX clusters. The replication is based on a schedule and is configured in global-mode and occurs directly from the active node on the active ARX cluster to the active and backup node on the backup ARX cluster. The target storage device for the replicated global-config is the system disk. Big-IP Global Traffic Managers (GTMs) are configured and synchronized, in conjunction with ARX configuration-replication, with ARX global-server DNS information redirecting end-users to the DR data center upon successful DR fail-over. In other words, once SiteB DR data center has been correctly provisioned and enabled with the ARX replication configuration, then the SiteB Global Traffic Manager is subsequently provisioned and made active as well as authoritative for the respective delegation domain name for the ARX global-config and respective active global-server at the DR site. See Figure 1 below illustrating a high-level F5 ARX/BIG-IP Global Traffic Manager Disaster Recovery fail-over design: Figure 1 – Disaster Recovery with F5 ARX and Big-IP Global Traffic Manager (GTM) Setup 1: ARX configuration-replication Below are the ARX GUI & CLI screen-shots for the F5 ARX configuration-replication feature: Setup 2: Global Traffic Manager (GTM) Wide-IPs for ARX Below is the GTM GUI screenshot representing 3 GTM Wide-IPs for ARX: 1. drdemo.arx.com = delegation domain that GTM is authoritative 2. arxvip1.drdemo.arx.com = SiteA ARX global-server 3. arxvip2.drdemo.arx.com = SiteB ARX global-server F5 ARX & GTM DNS Considerations A typical GTM deployment involves the creation of a DNS delegation domain under the current DNS domain. This allows the GTM to be the authoritative source for all records in the delegation domain. Server names that need to be converted to Wide-IP’s have their IP addresses moved to this delegation domain. When this is done the FQDN of the server being converted to a Wide-IP changes. The original server name is preserved using a CNAME alias. Most ARX deployments involve what is called a name-based takeover. In this situation the original filer server name is moved to the ARX and the file server is renamed. This allows the ARX to virtualize the existing file sever without requiring any changes to the clients that access this file server. In combined ARX/GTM deployments involving the use of Wide-IP’s, an additional step is required in order to preserve Kerberos authentication. Since the use of a Wide-IP involves changing the FQDN of the original file server, a Service Principle Name (SPN) alias also needs to be created in addition to a CNAME alias. The creation of the SPN alias allows the client to authenticate using Kerberos to the ARX virtual server using the original file server name. Example Original File Server: nas.arx.com File Server is renamed to: old-nas.arx.com WideIP File Server Name: nas.wideip.arx.com ARX VIP name becomes: nas.wideip.arx.com ARX VIP is joined to: arx.com ARX VIP AD machine account: nas in arx.com CNAME is created in arx.com DNS: nas.arx.com -> nas.wideip.arx.com SPN alias is created on nas.arx.com SPN: setspn –a HOST/nas.wideip.arx.com nas setspn –a CIFS/nas.wideip.arx.com nas Adding GTMs to an existing DNS environment There are two deployment methods for GTM. The first involves GTM becoming the primary DNS server for all of your clients. In the second case, GTM is only responsible for a sub-domain of the existing DNS environment. The second case is easier to deploy as it requires very few changes to the existing DNS environment. When using the second method, servers that host applications at multiple data centers are added to this new DNS subdomain. To preserve the original server name, CNAME aliases (See Figure 2 below) are created that point the original name to the new name that is part of the DNS subdomain. The existing DNS servers are then configured to delegate requests associated with the new DNS subdomain to the GTM devices. With this approach, no client changes are necessary and the GTM can be used to decide which IP address to return based on the defined health checks. Figure 2 - GTM configured as authoritative for a new ARX delegation domain Example If your domain is .arx.com and your website is www.arx.com the GTM becomes authoritative for a new delegation domain drdemo.arx.com. The DNS servers in ARX.COM are configured to delegate DNS requests for anything in drdemo.arx.com to the GTM devices. The GTM is configured with a Wide-IP www.drdemo.arx.com. The original DNS A record for www.arx.com is deleted and a CNAME is created in arx.com that points to www.drdemo.arx.com. Summary In summary, corporations that define and subsequently design their enterprise architecture, specific to storage management, while paying close attention to disaster recovery and how it relates to all components within the design (i.e. ARX config-replication/GTM synchronization/Storage replication) are essentially investing in a long-term cost-effective disaster recovery strategy. Corporations that have a well-defined disaster recovery plan in place and deployed ahead of time ensures minimal end-user downtime dramatically reducing recovery time and recovery point objective mandates. With the F5 ARX configuration-replication feature along with the Big IP Global Traffic Manager (GTM), F5 Networks provides IT administrators data center peace of mind ensuring simple site fail-over in the event of a primary site disaster and/or outage. Notes In the next installment of the F5 ARX /BIG-IP Global Traffic Manager (GTM) solution tech-tip, we will expand upon and highlight BIG-IP v11 and the DNSSEC & DNS Express feature sets as well as how they are applied and benefit an ARX/BIG-IP disaster recovery strategy. More information on these feature sets can be found at the links below: http://devcentral.f5.com/s/weblogs/macvittie/archive/2011/08/05/f5-friday-dns-express-ddos-protection.aspx http://www.f5.com/pdf/white-papers/dns-services-big-ip-v11-wp.pdf For additional information on F5 ARX and GTM please refer to the following links: http://www.f5.com/products/arx-series/ http://www.f5.com/products/big-ip/global-traffic-manager.html Author Bio Michael J. Fabiano is a pre-sales Sr. Corporate Systems Engineer for the F5 Data Solutions (ARX/Data Manager/ARX-CE) Sales business unit. Michael has been with F5 Networks just under 7 years and was also a Principal Test Engineer in the Product Development engineering organization. Prior to F5, Michael worked as a Sr. Interoperability Engineer at Pillar Data Systems (An Oracle Company) in San Jose, CA and was an Infrastructure Engineer at Genuity (formerly BBN/GTE Internetworking). Michael has a Master of Engineering degree from Northeastern University in SOA Governance & Enterprise Architecture.424Views0likes0Comments