Securing and Scaling Hybrid Application with F5 NGINX (Part 1)
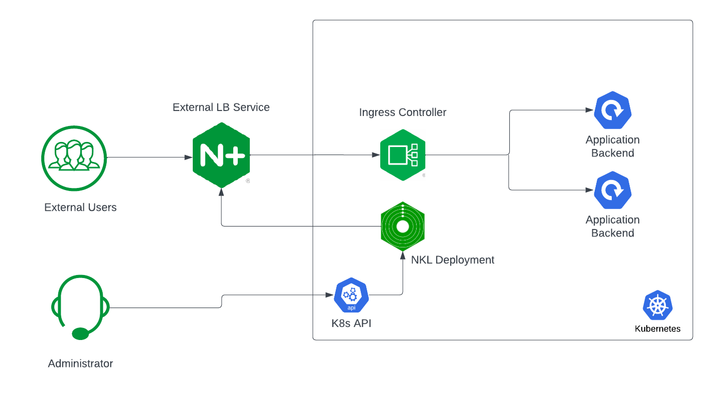
If you are using Kubernetes in production, then you are likely using an ingress controller. The ingress controller is the core engine managing traffic entering and exiting the Kubernetes cluster. Because the ingress controller is a deployment running inside the cluster, how do you route traffic to the ingress controller? How do you route external traffic to internal Kubernetes Services? Cloud providers offer a simple convenient way to expose Kubernetes Services using an external load balancer. Simply deploy a Managed Kubernetes Service (EKS, GKE, AKS) and create a Kubernetes Service of type LoadBalancer. The cloud providers will host and deploy a load balancer providing a public IP address. External users can connect to Kubernetes Services using this public entry point. However, this integration only applies to Managed Kubernetes Services hosted by cloud providers. If you are deploying Kubernetes in private cloud/on-prem environments, you will need to deploy your own load balancer and integrate it with the Kubernetes cluster. Furthermore, Kubernetes Load Balancing integrations in the cloud are limited to TCP Load Balancing and generally lack visibility into metrics, logs, and traces. We propose: A solution that applies regardless of the underlying infrastructure running your workloads Guidance around sizing to avoid bottlenecks from high traffic volumes Application delivery use cases that go beyond basic TCP/HTTP load balancing In the solution depicted below, I deploy NGINX Plus as the external LB service for Kubernetes and route traffic to the NGINX Ingress Controller. The NGINX Ingress Controller will then route the traffic to the application backends. The NLK (NGINX Load Balancer for Kubernetes) deployment is a new controller by NGINX that monitors specified Kubernetes Services and sends API calls to manage upstream endpoints of the NGINX External Load Balancer In this article, I will deploy the components both inside the Kubernetes cluster and NGINX Plus as the external load balancer. Note: I like to deploy both the NLK and Kubernetes cluster in the same subnet to avoid network issues. This is not a hard requirement. Prerequisites The blog assumes you have experience operating in Kubernetes environments. In addition, you have the following: Access to a Kubernetes environment; Bare Metal, Rancher Kubernetes Engine (RKE), VMWare Tanzu Kubernetes (VTK), Amazon Elastic Kubernetes (EKS), Google Kubernetes Engine (GKE), Microsoft Azure Kubernetes Service (AKS), and RedHat OpenShift NGINX Ingress Controller – Deploy NGINX Ingress Controller in the Kubernetes cluster. Installation instructions can be found in the documentation. NGINX Plus – Deploy NGINX Plus on VM or bare metal with SSH access. This will be the external LB service for the Kubernetes cluster. Installation instructions can be found in the documentation. You must have a valid license for NGINX Plus. You can get started today by requesting a 30-day free trial. Setting up the Kubernetes environment I start with deploying the back-end applications. You can deploy your own applications, or you can deploy our basic café application as an example. $ kubectl apply –f cafe.yaml Now I will configure routes and TLS settings for the ingress controller $ kubectl apply –f cafe-secret.yaml $ kubectl apply –f cafe-virtualserver.yaml To ensure the ingress rules are successfully applied, you can examine the output of kubectl get vs. The VirtualServer definition should be in the Valid state. NAMESPACE NAME STATE HOST IP PORTS default cafe-vs Valid cafe.example.com Setting up NGINX Plus as the external LB A fresh install of NGINX Plus will provide the default.conf file in the /etc/nginx/conf.d directory. We will add two additional files into this directory. Simply copy the bulleted files into your /etc/nginx/conf.d directory dashboard.conf; This will enable the real-time monitoring dashboard for NGINX Plus kube_lb.conf; The nginx configuration as the external load balancer for Kubernetes. You can change the configuration file to fit your requirements. In part 1 of this series, we enabled basic routing and TLS for one cluster. You will also need to generate TLS cert/keys and place them in the /etc/ssl/nginx folder of the NGINX Plus instance. For the sake of this example, we will generate a self-signed certificate with openssl. $ openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout default.key -out default.crt -subj "/CN=NLK" Note: Using self-signed certificates is for testing purposes only. In a live production environment, we recommend using a secure vault that will hold your secrets and trusted CAs (Certificate Authorities). Now I can validate the configuration and reload nginx for the changes to take effect. $ nginx –t $ nginx –s reload I can now connect to the NGINX Plus dashboard by opening a browser and entering http://<external-ip-nginx>:9000/dashboard.html#upstreams The HTTP upstream table should be empty as we have not deployed the NLK Controller yet. We will do that in the next section. Installing the NLK Controller You can install the NLK Controller as a Kubernetes deployment that will configure upstream endpoints for the external load balancer using the NGINX Plus API. First, we will create the NLK namespace $ kubectl create ns nlk And apply the RBAC settings for the NKL deployment $ kubectl apply -f serviceaccount.yaml $ kubectl apply -f clusterrole.yaml $ kubectl apply -f clusterrolebinding.yaml $ kubectl apply -f secret.yaml The next step is to create a ConfigMap defining the API endpoint of the NGINX Plus external load balancer. The API endpoint is used by the NLK Controller to configure the NGINX Plus upstream endpoints. We simply modify the nginx-hosts field in the manifest from our GitHub repository to the IP address of the NGINX external load balancer. nginx-hosts: http://<nginx-plus-external-ip>:9000/api Apply the updated ConfigMap and deploy the NLK controller $ kubectl apply –f nkl-configmap.yaml $ kubectl apply –f nkl-deployment I can verify the NLK controller deployment is running and the ConfigMap data is applied. $ kubectl get pods –o wide –n nlk $ kubectl describe cm nginx-config –n nlk You should see the NLK deployment in status Running and the URL should be defined under nginx-hosts. The URL is the NGINX Plus API endpoint of the external load Balancer. Now that the NKL Controller is successfully deployed, the external load balancer is ready to route traffic to the cluster. The final step is deploying a Kubernetes Service type NodePort to expose the Kubernetes cluster to NGINX Plus. $ kubectl apply –f nodeport.yaml There are a couple things to note about the NodePort Service manifest. Fields on line 7 and 14 are required for the NLK deployment to configure the external load balancer appropriately: The nginxinc.io/nkl-cluster annotation The port name matching the upstream block definition in the NGINX Plus configuration (See line 42 in kube_lb.conf) and preceding nkl- apiVersion: v1 kind: Service metadata: name: nginx-ingress namespace: nginx-ingress annotations: nginxinc.io/nlk-cluster1-https: "http" # Must be added spec: type: NodePort ports: - port: 443 targetPort: 443 protocol: TCP name: nlk-cluster1-https selector: app: nginx-ingress Once the service is applied, you can note down the assigned nodeport selecting the NGINX Ingress Controller deployment. In this example, that node port is 32222. $ kubectl get svc –o wide –n nginx-ingress NAME TYPE CLUSTER-IP PORT(S) SELECTOR nginx-ingress NodePort x.x.x.x 443:32222/TCP app=nginx-ingress If I reconnect to my NGINX Pus dashboard, the upstream tab should be populated with the worker node IPs of the Kubernetes cluster and matching the node port of the nginx-ingress Service (32222). You can list the node IPs of your cluster to make sure they match the IPs in the dashboard upstream tab. $ kubectl get nodes -o wide | awk '{print $6}' INTERNAL-IP 10.224.0.6 10.224.0.5 10.224.0.4 Now I can connect to the Kubernetes application from our local machine. The hostname we used in our example (cafe.example.com) should resolve to the IP address of the NGINX Plus load balancer. Wrapping it up Most enterprises deploying Kubernetes in production will install an ingress controller. It is the DeFacto standard for application delivery in container orchestrators like Kubernetes. DevOps/NetOps engineers are now looking for guidance on how to scale out their Kubernetes footprint in the most efficient way possible. Because enterprises are embracing the hybrid approach, they will need to implement their own integrations outside of cloud providers. The solution we propose: is applicable to hybrid environments (particularly on-prem) Sizing information to avoid bottlenecks from large traffic volumes Enterprise Load Balancing capabilities that stretch beyond a TCP LoadBalancing Service In the next part of our series, I will dive into the third bullet point into much more detail and cover Zero Trust use cases with NGINX Plus, providing extra later of security in your hybrid model.169Views0likes0CommentsF5 NGINXaaS for Azure: Multi-Region Architecture
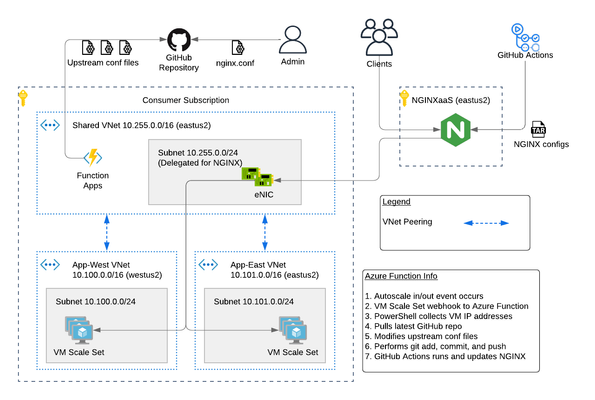
The F5 NGINXaaS for Azureoffering recently announced general availability. Trust me...I've been using it and having fun! In this article, I will show you an example hub and spoke architecture using GitHub Actions and Azure Functions to automate NGINX configurations. As a bonus, I have code on GitHub that you can use to deploy this example. Topics Covered: NGINXaaS for Azure Architecture Explained The NGINXaaS for Azure architecture consists of an F5 subscription as well as customer subscription. F5 subscription - hidden from user, NGINX Plus instances, control plane, data plane Customer subscription - eNICs from VNet Injection, customer network stack, customer workloads F5 Subscription The NGINXaaS offering createsNGINX Plus instances and other related components like NGINX control plane and data plane resources in the F5 subscriptions. These items are not visible to the end user, and therefore result in the operational tasks of upgrades and scaling being managed by the NGINXaaS offering instead of the user. Each NGINX deployment, like other Azure services, is regional in nature. If you need to deploy NGINX closer to the client, then this will require multiple NGINX deployments (ex. westus2, eastus2). Each NGINX deployment will have a unique listener address. You can then use DNS to send clients to an NGINX deployment in the nearest region. Here is an example diagram. Customer Subscription The customer subscription has items like network stacks, Key Vaults, monitoring, application workloads, and more. The NGINX deployment automatically creates ethernet NICs (eNICs) in the customer subscription using VNet Injection and subnet delegation. The eNICs are deployed inside their own Azure Resource Group. They receive IP addressing from the customer VNet and are indeed visible by the user. However, there is no management needed with the eNICs because they are part of the NGINX deployment. Note: In my testing during public preview, I have noticed that Azure lets you manually remove subnet delegation for the NGINX service. Warning...do NOT do this. It will break traffic flow. Hub and Spoke Architecture You can easily make a hub and spoke design with NGINX in the mix using VNet peering. This is a great use case when required to use a shared NGINX deployment across different VNets, environments, or scaling workloads across multiple regions. Recall from earlier that an NGINX deployment will automatically create eNICs in the customer subscription. Therefore, you can control the entry point into the customer environment and the traffic flows. For example, configuring NGINX to use a customer shared VNet with peering gives you a hub and spoke design such as the picture below. This results in the NGINX eNICs being deployed into a customer Shared VNet (hub). Meanwhile the customer places workloads into their own VNets (spokes). Demo Code If this is the first time deploying NGINXaaS for Azure in your subscription, then you will need to subscribe to it in the marketplace. Search for “F5 NGINXaaS for Azure” in marketplace or follow this link Select F5 NGINXaaS for Azure and choose "Public Preview" and subscribe Time to play with code! Click the link below and review the README to deploy the demo example.There are prerequisites to follow. For example, you need to have a GitHub repository that stores the NGINX configuration files. You also need to have an Azure Key Vault and secret containing your GitHub access token. These are explained in the README. GitHub repo - F5 NGINXaaS for Azure Deployment with Demo Application in Multiple Regions After the deployment is done, you have a few options on how to handle NGINX configurations. I will share examples in future articles, but for now go ahead and explore on your own. Refer to the NGINXaaS for Azure documentation "NGINX Configuration" to get started. Summary This article gives an example architecture for deploying the NGINXaaS for Azure offering. I shared details on the different NGINX components, and I also shared demo code to help you explore the solution on your own! Contact us with any questions or requirements. We would love to hear from you! Resources DevCentral Series - F5 NGINXaaS for Azure F5 NGINXaaS for Azure Docs Blog Introducing F5 NGINXaaS for Azure3.1KViews6likes2CommentsF5 High Availability - Public Cloud Guidance
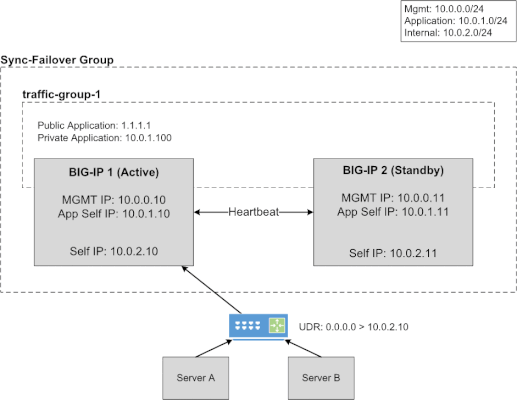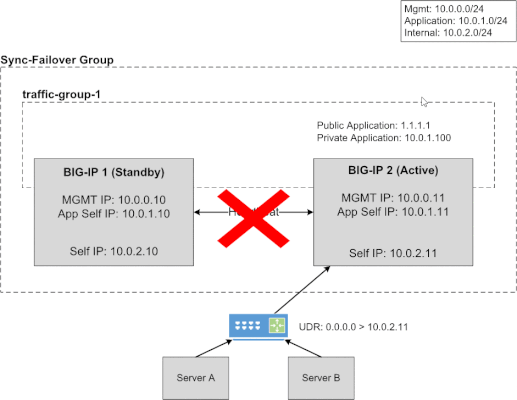
This article will provide information about BIG-IP and NGINX high availability (HA) topics that should be considered when leveraging the public cloud. There are differences between on-prem and public cloud such as cloud provider L2 networking. These differences lead to challenges in how you address HA, failover time, peer setup, scaling options, and application state. Topics Covered: Discuss and Define HA Importance of Application Behavior and Traffic Sizing HA Capabilities of BIG-IP and NGINX Various HA Deployment Options (Active/Active, Active/Standby, auto scale) Example Customer Scenario What is High Availability? High availability can mean many things to different people. Depending on the application and traffic requirements, HA requires dual data paths, redundant storage, redundant power, and compute. It means the ability to survive a failure, maintenance windows should be seamless to user, and the user experience should never suffer...ever! Reference: https://en.wikipedia.org/wiki/High_availability So what should HA provide? Synchronization of configuration data to peers (ex. configs objects) Synchronization of application session state (ex. persistence records) Enable traffic to fail over to a peer Locally, allow clusters of devices to act and appear as one unit Globally, disburse traffic via DNS and routing Importance of Application Behavior and Traffic Sizing Let's look at a common use case... "gaming app, lots of persistent connections, client needs to hit same backend throughout entire game session" Session State The requirement of session state is common across applications using methods like HTTP cookies,F5 iRule persistence, JSessionID, IP affinity, or hash. The session type used by the application can help you decide what migration path is right for you. Is this an app more fitting for a lift-n-shift approach...Rehost? Can the app be redesigned to take advantage of all native IaaS and PaaS technologies...Refactor? Reference: 6 R's of a Cloud Migration Application session state allows user to have a consistent and reliable experience Auto scaling L7 proxies (BIG-IP or NGINX) keep track of session state BIG-IP can only mirror session state to next device in cluster NGINX can mirror state to all devices in cluster (via zone sync) Traffic Sizing The cloud provider does a great job with things like scaling, but there are still cloud provider limits that affect sizing and machine instance types to keep in mind. BIG-IP and NGINX are considered network virtual appliances (NVA). They carry quota limits like other cloud objects. Google GCP VPC Resource Limits Azure VM Flow Limits AWS Instance Types Unfortunately, not all limits are documented. Key metrics for L7 proxies are typically SSL stats, throughput, connection type, and connection count. Collecting these application and traffic metrics can help identify the correct instance type. We have a list of the F5 supported BIG-IP VE platforms on F5 CloudDocs. F5 Products and HA Capabilities BIG-IP HA Capabilities BIG-IP supports the following HA cluster configurations: Active/Active - all devices processing traffic Active/Standby - one device processes traffic, others wait in standby Configuration sync to all devices in cluster L3/L4 connection sharing to next device in cluster (ex. avoids re-login) L5-L7 state sharing to next device in cluster (ex. IP persistence, SSL persistence, iRule UIE persistence) Reference: BIG-IP High Availability Docs NGINX HA Capabilities NGINX supports the following HA cluster configurations: Active/Active - all devices processing traffic Active/Standby - one device processes traffic, others wait in standby Configuration sync to all devices in cluster Mirroring connections at L3/L4 not available Mirroring session state to ALL devices in cluster using Zone Synchronization Module (NGINX Plus R15) Reference: NGINX High Availability Docs HA Methods for BIG-IP In the following sections, I will illustrate 3 common deployment configurations for BIG-IP in public cloud. HA for BIG-IP Design #1 - Active/Standby via API HA for BIG-IP Design #2 - A/A or A/S via LB HA for BIG-IP Design #3 - Regional Failover (multi region) HA for BIG-IP Design #1 - Active/Standby via API (multi AZ) This failover method uses API calls to communicate with the cloud provider and move objects (IP address, routes, etc) during failover events. The F5 Cloud Failover Extension (CFE) for BIG-IP is used to declaratively configure the HA settings. Cloud provider load balancer is NOT required Fail over time can be SLOW! Only one device actively used (other device sits idle) Failover uses API calls to move cloud objects, times vary (see CFE Performance and Sizing) Key Findings: Google API failover times depend on number of forwarding rules Azure API slow to disassociate/associate IPs to NICs (remapping) Azure API fast when updating routes (UDR, user defined routes) AWS reliable with API regarding IP moves and routes Recommendations: This design with multi AZ is more preferred than single AZ Recommend when "traditional" HA cluster required or Lift-n-Shift...Rehost For Azure (based on my testing)... Recommend using Azure UDR versus IP failover when possible Look at Failover via LB example instead for Azure If API method required, look at DNS solutions to provide further redundancy HA for BIG-IP Design #2 - A/A or A/S via LB (multi AZ) Cloud LB health checks the BIG-IP for up/down status Faster failover times (depends on cloud LB health timers) Cloud LB allows A/A or A/S Key difference: Increased network/compute redundancy Cloud load balancer required Recommendations: Use "failover via LB" if you require faster failover times For Google (based on my testing)... Recommend against "via LB" for IPSEC traffic (Google LB not supported) If load balancing IPSEC, then use "via API" or "via DNS" failover methods HA for BIG-IP Design #3 - Regional Failover via DNS (multi AZ, multi region) BIG-IP VE active/active in multiple regions Traffic disbursed to VEs by DNS/GSLB DNS/GSLB intelligent health checks for the VEs Key difference: Cloud LB is not required DNS logic required by clients Orchestration required to manage configs across each BIG-IP BIG-IP standalone devices (no DSC cluster limitations) Recommendations: Good for apps that handle DNS resolution well upon failover events Recommend when cloud LB cannot handle a particular protocol Recommend when customer is already using DNS to direct traffic Recommend for applications that have been refactored to handle session state outside of BIG-IP Recommend for customers with in-house skillset to orchestrate (Ansible, Terraform, etc) HA Methods for NGINX In the following sections, I will illustrate 2 common deployment configurations for NGINX in public cloud. HA for NGINX Design #1 - Active/Standby via API HA for NGINX Design #2 - Auto Scale Active/Active via LB HA for NGINX Design #1 - Active/Standby via API (multi AZ) NGINX Plus required Cloud provider load balancer is NOT required Only one device actively used (other device sits idle) Only available in AWS currently Recommendations: Recommend when "traditional" HA cluster required or Lift-n-Shift...Rehost Reference: Active-Passive HA for NGINX Plus on AWS HA for NGINX Design #2 - Auto Scale Active/Active via LB (multi AZ) NGINX Plus required Cloud LB health checks the NGINX Faster failover times Key difference: Increased network/compute redundancy Cloud load balancer required Recommendations: Recommended for apps fitting a migration type of Replatform or Refactor Reference: Active-Active HA for NGINX Plus on AWS, Active-Active HA for NGINX Plus on Google Pros & Cons: Public Cloud Scaling Options Review this handy table to understand the high level pros and cons of each deployment method. Example Customer Scenario #1 As a means to make this topic a little more real, here isa common customer scenario that shows you the decisions that go into moving an application to the public cloud. Sometimes it's as easy as a lift-n-shift, other times you might need to do a little more work. In general, public cloud is not on-prem and things might need some tweaking. Hopefully this example will give you some pointers and guidance on your next app migration to the cloud. Current Setup: Gaming applications F5 Hardware BIG-IP VIRPIONs on-prem Two data centers for HA redundancy iRule heavy configuration (TLS encryption/decryption, payload inspections) Session Persistence = iRule Universal Persistence (UIE), and other methods Biggest app 15K SSL TPS 15Gbps throughput 2 million concurrent connections 300K HTTP req/sec (L7 with TLS) Requirements for Successful Cloud Migration: Support current traffic numbers Support future target traffic growth Must run in multiple geographic regions Maintain session state Must retain all iRules in use Recommended Design for Cloud Phase #1: Migration Type: Hybrid model, on-prem + cloud, and some Rehost Platform: BIG-IP Retaining iRules means BIG-IP is required Licensing: High Performance BIG-IP Unlocks additional CPU cores past 8 (up to 24) extra traffic and SSL processing Instance type: check F5 supported BIG-IP VE platforms for accelerated networking (10Gb+) HA method: Active/Standby and multi-region with DNS iRule Universal persistence only mirrors to only next device, keep cluster size to 2 scale horizontally via additional HA clusters and DNS clients pinned to a region via DNS (on-prem or public cloud) inside region, local proxy cluster shares state This example comes up in customer conversations often. Based on customer requirements, in-house skillset, current operational model, and time frames there is one option that is better than the rest. A second design phase lends itself to more of a Replatform or Refactor migration type. In that case, more options can be leveraged to take advantage of cloud-native features. For example, changing the application persistence type from iRule UIE to cookie would allow BIG-IP to avoid keeping track of state. Why? With cookies, the client keeps track of that session state. Client receives a cookie, passes the cookie to L7 proxy on successive requests, proxy checks cookie value, sends to backend pool member. The requirement for L7 proxy to share session state is now removed. Example Customer Scenario #2 Here is another customer scenario. This time the application is a full suite of multimedia content. In contrast to the first scenario, this one will illustrate the benefits of rearchitecting various components allowing greater flexibility when leveraging the cloud. You still must factor in-house skill set, project time frames, and other important business (and application) requirements when deciding on the best migration type. Current Setup: Multimedia (Gaming, Movie, TV, Music) Platform BIG-IP VIPRIONs using vCMP on-prem Two data centers for HA redundancy iRule heavy (Security, Traffic Manipulation, Performance) Biggest App: oAuth + Cassandra for token storage (entitlements) Requirements for Success Cloud Migration: Support current traffic numbers Elastic auto scale for seasonal growth (ex. holidays) VPC peering with partners (must also bypass Web Application Firewall) Must support current or similar traffic manipulating in data plane Compatibility with existing tooling used by Business Recommended Design for Cloud Phase #1: Migration Type: Repurchase, migration BIG-IP to NGINX Plus Platform: NGINX iRules converted to JS or LUA Licensing: NGINX Plus Modules: GeoIP, LUA, JavaScript HA method: N+1 Autoscaling via Native LB Active Health Checks This is a great example of a Repurchase in which application characteristics can allow the various teams to explore alternative cloud migration approaches. In this scenario, it describes a phase one migration of converting BIG-IP devices to NGINX Plus devices. This example assumes the BIG-IP configurations can be somewhat easily converted to NGINX Plus, and it also assumes there is available skillset and project time allocated to properly rearchitect the application where needed. Summary OK! Brains are expanding...hopefully? We learned about high availability and what that means for applications and user experience. We touched on the importance of application behavior and traffic sizing. Then we explored the various F5 products, how they handle HA, and HA designs. These recommendations are based on my own lab testing and interactions with customers. Every scenario will carry its own requirements, and all options should be carefully considered when leveraging the public cloud. Finally, we looked at a customer scenario, discussed requirements, and design proposal. Fun! Resources Read the following articles for more guidance specific to the various cloud providers. Advanced Topologies and More on Highly Available Services Lightboard Lessons - BIG-IP Deployments in Azure Google and BIG-IP Failing Faster in the Cloud BIG-IP VE on Public Cloud High-Availability Load Balancing with NGINX Plus on Google Cloud Platform Using AWS Quick Starts to Deploy NGINX Plus NGINX on Azure5.2KViews5likes2CommentsMitigating OWASP API Security Top 10 risks using F5 NGINX App Protect
This 2019 API Security article covers the summary of OWASP API Security Top 10 – 2019 categories and newly published 2023 API security article covered introductory part of newest edition of OWASP API Security Top 10 risks – 2023. We will deep-dive into some of those common risks and how we can protect our applications against these vulnerabilities using F5 NGINX App Protect. Excessive Data Exposure Problem Statement: As shown below in one of the demo application API’s, Personal Identifiable Information (PII) data, like Credit Card Numbers (CCN) and U.S. Social Security Numbers (SSN), are visible in responses that are highly sensitive. So, we must hide these details to prevent personal data exploits. Solution: To prevent this vulnerability, we will use the DataGuard feature in NGINX App Protect, which validates all response data for sensitive details and will either mask the data or block those requests, as per the configured settings. First, we will configure DataGuard to mask the PII data as shown below and will apply this configuration. Next, if we resend the same request, we can see that the CCN/SSN numbers are masked, thereby preventing data breaches. If needed, we can update configurations to block this vulnerability after which all incoming requests for this endpoint will be blocked. If you open the security log and filter with this support ID, we can see that the request is either blocked or PII data is masked, as per the DataGuard configuration applied in the above section. Injection Problem Statement: Customer login pages without secure coding practices may have flaws. Intruders could use those flaws to exploit credential validation using different types of injections, like SQLi, command injections, etc. In our demo application, we have found an exploit which allows us to bypass credential validation using SQL injection (by using username as “' OR true --” and any password), thereby getting administrative access, as below: Solution: NGINX App Protect has a database of signatures that match this type of SQLi attacks. By configuring the WAF policy in blocking mode, NGINX App Protect can identify and block this attack, as shown below. If you check in the security log with this support ID, we can see that request is blocked because of SQL injection risk, as below. Insufficient Logging & Monitoring Problem Statement: Appropriate logging and monitoring solutions play a pivotal role in identifying attacks and also in finding the root cause for any security issues. Without these solutions, applications are fully exposed to attackers and SecOps is completely blind to identifying details of users and resources being accessed. Solution: NGINX provides different options to track logging details of applications for end-to-end visibility of every request both from a security and performance perspective. Users can change configurations as per their requirements and can also configure different logging mechanisms with different levels. Check the links below for more details on logging: https://www.nginx.com/blog/logging-upstream-nginx-traffic-cdn77/ https://www.nginx.com/blog/modsecurity-logging-and-debugging/ https://www.nginx.com/blog/using-nginx-logging-for-application-performance-monitoring/ https://docs.nginx.com/nginx/admin-guide/monitoring/logging/ https://docs.nginx.com/nginx-app-protect-waf/logging-overview/logs-overview/ Unrestricted Access to Sensitive Business Flows Problem Statement: By using the power of automation tools, attackers can now break through tough levels of protection. The inefficiency of APIs to detect automated bot tools not only causes business loss, but it can also adversely impact the services for genuine users of an application. Solution: NGINX App Protect has the best-in-class bot detection technology and can detect and label automation tools in different categories, like trusted, untrusted, and unknown. Depending on the appropriate configurations applied in the policy, requests generated from these tools are either blocked or alerted. Below is an example that shows how requests generated from the Postman automation tool are getting blocked. By filtering the security log with this support-id, we can see that the request is blocked because of an untrusted bot. Lack of Resources & Rate Limiting Problem Statement: APIs do not have any restrictions on the size or number of resources that can be requested by the end user. Above mentioned scenarios sometimes lead to poor API server performance, Denial of Service (DoS), and brute force attacks. Solution: NGINX App Protect provides different ways to rate limit the requests as per user requirements. A simple rate limiting use case configuration is able to block requests after reaching the limit, which is demonstrated below. Conclusion: In short, this article covered some common API vulnerabilities and shows how NGINX App Protect can be used as a mitigation solution to prevent these OWASP API security risks. Related resources for more information or to get started: F5 NGINX App Protect OWASP API Security Top 10 2019 OWASP API Security Top 10 20232.2KViews6likes0CommentsApplication Programming Interface (API) Authentication types simplified
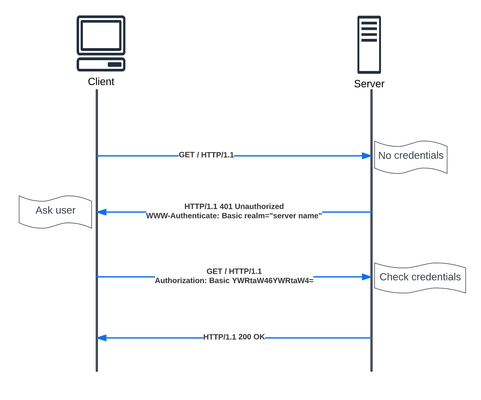
API is a critical part of most of our modern applications. In this article we will walkthrough the different authentication types, to help us in the future articles covering NGINX API Connectivity Manager authentication and NGINX Single Sign-on.3.9KViews5likes0CommentsNGINX Management Suite API Connectivity Manager - Modern API driven Applications
Introduction API based applications benefits NGINX Management Suite API Connectivity Manager capabilities API Connectivity Manager use case API Connectivity Manager use case overview API Connectivity Manager traffic flows API Connectivity Manager lab & implementation References Introduction API based applications benefits Before we dive into our API gateway use case, we will go one step back and check why the move to API driven applications, below are some of the benefits for this move: Loose coupling: API-based applications can be built and maintained independently, allowing for faster development and deployment cycles. Reusability: APIs can be reused across multiple applications, reducing the need to duplicate code and effort. Scalability: API-based architecture allows for easier scaling of individual services, rather than having to scale the entire application. Flexibility: APIs allow for different client applications to consume the same services, such as web, mobile, and IoT devices. Interoperability: APIs facilitate communication between different systems and platforms, enabling integration with third-party services and data sources. Microservices: API-based architecture allows developers to build small, modular services that can be developed, deployed, and scaled independently. NGINX Management Suite API Connectivity Manager capabilities NGINX Management Suite API Connectivity Manager adds to the capabilities of the API driven applications a secure approach to authenticate, access and developing those API based applications. API Connectivity Manager is used to connect, secure, and govern our APIs. In addition, API Connectivity Manager lets us separate infrastructure lifecycle management from the API lifecycle, giving the IT/Ops teams and application developers the ability to work independently. API Connectivity Manager provides the following features: Create and manage isolated Workspaces for business units, development teams, and so on, so each team can develop and deploy at its own pace without affecting other teams. Create and manage API infrastructure in isolated workspaces. Enforce uniform security policies across all workspaces by applying global policies. Create Developer Portals that align with your brand, with custom color themes, logos, and favicons. Onboard your APIs to an API Gateway cluster and publish your API documentation to the Dev Portal. Let teams apply policies to their API proxies to provide custom quality of service for individual applications. Onboard API documentation by uploading an OpenAPI spec. Publish your API docs to a Dev Portal while keeping your API’s backend service private. Let users issue API keys or basic authentication credentials for access to your API. Send API calls by using the Developer Portal’s API Reference documentation. API Connectivity Manager use case API Connectivity Manager use case overview In our case we will have three teams, Infrastructure team, this one will be responsible for setting up the infrastructure, domains and access policies. API team, this one will be responsible for setting up the API documentation, QoS and gateway for both production and developer portals. Application team, this one will be responsible for learning the APIs through the developer portal and use the APIs through the production portal. Authentication in our case is done via two methods, API Key authentication for API version 1. OAuth2 introspection for API version 2. Note, More Authentication methods can be used (JSON Web Token Assertion) included in the following tutorial. API authentication more detailed discussion can be found here Application Programming Interface (API) Authentication types simplified Additional features like API rate limiting can be applied as well, here's a toturial to enable that feature. API Connectivity Manager traffic flows In our use case will have three flows, Management flow, illustrated below. Metrics and events collection flow, illustrated below Data flow illustrated below NGINX tutorial on how to streamline API operations with API Connectivity Manager, API Connectivity Manager lab & implementation ِThe steps we are going to follow with some useful tutorial videos are highlighted below, Setup backend API application (This step has been already done for you in the lab). Setup API Connectivity Manager infrastructure and policies. Enable API Key Authentication via the following Youtube toturial Enable API Key Authentication with API Connectivity Manager. Publish APIs and Documentation through API Connectivity Manager. Test APIs through API Developer Portal The detailed lab guide and the implementation videos Cloud labs detailed guide https://clouddocs.f5.com/training/community/nginx/html/class10/class10.html UDF lab can be found here as well https://udf.f5.com/b/ed5ffb71-bcce-47ec-9d9f-307441e4c12c#documentation Below a recorded Lab walkthrough by our awesome guru Matt_Dierick References API Connectivity Manager NGINX Management Suite NGINX Docs API Connectivity Manager UDF Lab 1.7KViews7likes0Comments
1.7KViews7likes0Comments2022 DevCentral MVP Announcement
Congratulations to the 2022 DevCentral MVPs! Without users who take time from their busy days to share their experience and knowledge for others, DevCentral would be more of a corporate news site and not an actual user community. To that end, the DevCentral MVP Award is given annually to the outstanding group of individuals – the experts in the technical F5 user community who go out of their way to engage with the user community. The award is our way of recognizing their significant contributions, because while all of our users collectively make DevCentral one of the top community sites around and a valuable resource for everyone, MVPs regularly go above and beyond in assisting fellow F5 users.We understand that 2021 was difficult for everyone, and we are extra-grateful to this year's MVPs for going out of their ways to help others. MVPs get badges in their DevCentral profiles so everyone can see that they are recognized experts. This year’s MVPs will receive a glass award, certificate, exclusive thank-you gifts, and invitations to exclusive webinars and behind-the-scenes looks at things like roadmaps, new product sneak-previews, and innovative concepts in development. The 2022 DevCentral MVPs are: Aditya K Vlogs AlexBCT Amine_Kadimi Austin_Geraci Boneyard Daniel_Wolf Dario_Garrido David.burgoyne Donamato 01 Enes_Afsin_Al FrancisD iaine jaikumar_f5 Jim_Schwartzme1 JoshBecigneul JTLampe Kai Wilke Kees van den Bos Kevin_Davies Lionel Deval (Lidev) LouisK Mayur_Sutare Neeeewbie Niels_van_Sluis Nikoolayy1 P K Patrik_Jonsson Philip Jönsson Rob_Carr Rodolfo_Nützmann Rodrigo_Albuquerque Samstep SanjayP ScottE Sebastian Maniak Stefan_Klotz StephanManthey Tyler.Hatton1.2KViews8likes0CommentsDeploying NGINX Ingress Controller with OpenShift on AWS Managed Service: ROSA
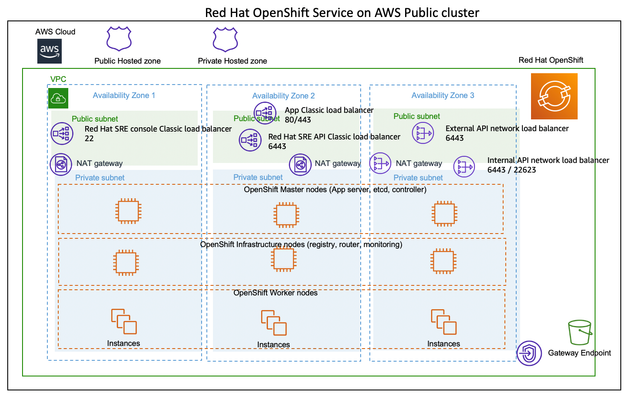
Introduction In March 2021, Amazon and Red Hat announced the General Availability of Red Hat OpenShift Service on AWS (ROSA). ROSA is a fully-managed OpenShift service, jointly managed and supported by both Red Hat and Amazon Web Services (AWS). OpenShift offers users several different deployment models. For customers that require a high degree of customization and have the skill sets to manage their environment, they can build and manage OpenShift Container Platform (OCP) on AWS. For those who want to alleviate the complexity in managing the environment and focus on their applications, they can consume OpenShift as a service, or Red Hat OpenShift Service on AWS (ROSA). The benefits of ROSA are two-fold. First, we can enjoy more simplified Kubernetes cluster creation using the familiar Red Hat OpenShift console, features, and tooling without the burden of manually scaling and managing the underlying infrastructure. Secondly,the managed service made easier with joint billing, support, and out-of-the-box integration to AWS infrastructure and services. In this article, I am exploring how to deploy an environment with NGINX Ingress Controller integrated into ROSA. Deploy Red Hat OpenShift Service on AWS (ROSA) The ROSA service may be deployed directly from the AWS console.Red Hat has done a great job in providing the instructions on creating a ROSA cluster in the Installation Guide. The guide documents the AWS prerequisites, required AWS service quotas, and configuration of your AWS accounts. We run the following commands to ensure that the prerequisites are met before installing ROSA. -Verify that my AWS account has the necessary permissions: ❯ rosa verify permissions I: Validating SCP policies... I: AWS SCP policies ok -Verify that my AWS account has the necessary quota to deploy a Red Hat OpenShift Service on the AWS cluster. ❯ rosa verify quota --region=us-west-2 I: Validating AWS quota... I: AWS quota ok. If cluster installation fails, validate actual AWS resource usage against https://docs.openshift.com/rosa/rosa_getting_started/rosa-required-aws-service-quotas.html Next, I ran the following command to prepare my AWS account for cluster deployment: ❯ rosa init I: Logged in as 'ericji' on 'https://api.openshift.com' I: Validating AWS credentials... I: AWS credentials are valid! I: Validating SCP policies... I: AWS SCP policies ok I: Validating AWS quota... I: AWS quota ok. If cluster installation fails, validate actual AWS resource usage against https://docs.openshift.com/rosa/rosa_getting_started/rosa-required-aws-service-quotas.html I: Ensuring cluster administrator user 'osdCcsAdmin'... I: Admin user 'osdCcsAdmin' created successfully! I: Validating SCP policies for 'osdCcsAdmin'... I: AWS SCP policies ok I: Validating cluster creation... I: Cluster creation valid I: Verifying whether OpenShift command-line tool is available... I: Current OpenShift Client Version: 4.7.19 If we were to follow their instructions to create a ROSA cluster using therosaCLI, after about 35 minutes our deployment would produce a Red Hat OpenShift cluster along with the needed AWS components. ❯ rosa create cluster --cluster-name=eric-rosa I: Creating cluster 'eric-rosa' I: To view a list of clusters and their status, run 'rosa list clusters' I: Cluster 'eric-rosa' has been created. I: Once the cluster is installed you will need to add an Identity Provider before you can login into the cluster. See 'rosa create idp --help' for more information. I: To determine when your cluster is Ready, run 'rosa describe cluster -c eric-rosa'. I: To watch your cluster installation logs, run 'rosa logs install -c eric-rosa --watch'. Name:eric-rosa … During the deployment, we may enter the following command to follow the OpenShift installer logs to track the progress of our cluster: > rosa logs install -c eric-rosa --watch After the Red Hat OpenShift Service on AWS (ROSA) cluster is created, we must configure identity providers to determine how users log in to access the cluster. What just happened? Let's review what just happened. The above installation programautomatically set up the following AWS resources for the ROSA environment: AWS VPC subnets per Availability Zone (AZ). For single AZ implementations two subnets were created (one public one private) The multi-AZ implementation would make use of three Availability Zones, with a public and private subnet in each AZ (a total of six subnets). OpenShift cluster nodes (or EC2 instances) Three Master nodes were created to cater for cluster quorum and to ensure proper fail-over and resilience of OpenShift. At least two infrastructure nodes, catering for build-in OpenShift container registry, OpenShift router layer, and monitoring. Multi-AZ implementations Three Master nodes and three infrastructure nodes spread across three AZs Assuming that application workloads will also be running in all three AZs for resilience, this will deploy three Workers. This will translate to a minimum of nine EC2 instances running within the customer account. A collection ofAWS Elastic Load Balancers, some of these Load balancers will provide end-user access to the application workloads running on OpenShift via the OpenShift router layer, other AWS elastic load balancers will expose endpoints used for cluster administration and management by the SRE teams. Source:https://aws.amazon.com/blogs/containers/red-hat-openshift-service-on-aws-architecture-and-networking/ Deploy NGINX Ingress Controller The NGINX Ingress Operator is a supported and certified mechanism for deployingNGINX Ingress Controller in an OpenShift environment, with point-and-click installation and automatic upgrades. It works for both the NGINX Open Source-basedand NGINX Plus-basededitionsof NGINX Ingress Controller. In thistutorial, I’ll bedeploying theNGINX Plus-based edition.ReadWhy You Need an Enterprise-Grade Ingress Controller on OpenShiftforuse casesthat merit the use of this edition.If you’re not sure how these editions are different, readWait, Which NGINX Ingress Controller for Kubernetes Am I Using? Iinstall the NGINX Ingress Operator from the OpenShift console.There are numerous options you can set when configuring the NGINX Ingress Controller, as listedinour GitHubrepo.Here is a manifestexample: apiVersion: k8s.nginx.org/v1alpha1 kind: NginxIngressController metadata: name: my-nginx-ingress-controller namespace: openshift-operators spec: ingressClass: nginx serviceType: LoadBalancer nginxPlus: true type: deployment image: pullPolicy: Always repository: ericzji/nginx-plus-ingress tag: 1.12.0 To verify the deployment, run the following commands in a terminal. As shown in the output, the manifest I used in the previous step deployed two replicas of the NGINX Ingress Controller and exposed them with aLoadBalancerservice. ❯ oc get pods -n openshift-operators NAMEREADYSTATUSRESTARTSAGE my-nginx-ingress-controller-b556f8bb-bsn4k1/1Running014m nginx-ingress-operator-controller-manager-7844f95d5f-pfczr2/2Running03d5h ❯ oc get svc -n openshift-operators NAMETYPECLUSTER-IPEXTERNAL-IPPORT(S)AGE my-nginx-ingress-controllerLoadBalancer172.30.171.237a2b3679e50d36446d99d105d5a76d17f-1690020410.us-west-2.elb.amazonaws.com80:30860/TCP,443:30143/TCP25h nginx-ingress-operator-controller-manager-metrics-serviceClusterIP172.30.50.231<none> With NGINX Ingress Controller deployed, we'll have an environment that looks like this: Post-deployment verification After the ROSA cluster was configured, I deployed an app (Hipster) in OpenShift that is exposed by NGINX Ingress Controller (by creating an Ingress resource). To use a custom hostname,it requires that we manually change your DNS record on the Internetto point to the IP address value of AWS Elastic Load Balancer. ❯ dig +short a2dc51124360841468c684127c4a8c13-808882247.us-west-2.elb.amazonaws.com 34.209.171.103 52.39.87.162 35.164.231.54 I made this DNS change (optionally, use a local host record), and we will see my demo app available on the Internet, like this: Deleting your environment To avoid unexpected charges, don't forget to delete your environment if you no longer need it. ❯ rosa delete cluster -c eric-rosa --watch ? Are you sure you want to delete cluster eric-rosa? Yes I: Cluster 'eric-rosa' will start uninstalling now W: Logs for cluster 'eric-rosa' are not available … Conclusion To summarize, ROSA allows infrastructure and security teams to accelerate the deployment of the Red Hat OpenShift Service on AWS. Integration with NGINX Ingress Controller provides comprehensive L4-L7 security services for the application workloads running on Red Hat OpenShift Service on AWS (ROSA). As a developer, having your clusters as well as security services maintained by this service gives you the freedom to focus on deploying applications. You have two options for gettingstarted with NGINX Ingress Controller: Download the NGINX Open Source-based version of NGINX Ingress Controller fromour GitHub repo. If you prefer to bring your own license to AWS,get a free trialdirectly from F5 NGINX.4.8KViews0likes0Comments