Lightboard Lessons: BIG-IP Deployments in Azure Cloud
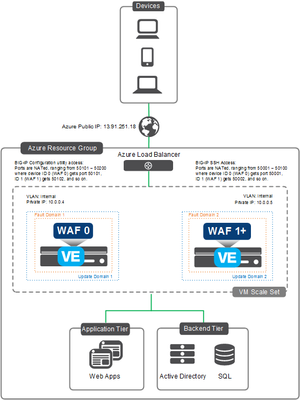
In this edition of Lightboard Lessons, I cover the deployment of a BIG-IP in Azure cloud. There are a few videos associated with this topic, and each video will address a specific use case. Topics will include the following: Azure Overview with BIG-IP BIG-IP High Availability Failover Methods Glossary: ALB = Azure Load Balancer ILB = Azure Internal Load Balancer HA = High Availability VE = Virtual Edition NVA = Network Virtual Appliance DSR = Direct Server Return RT = Route Table UDR = User Defined Route WAF = Web Application Firewall Azure Overview with BIG-IP This overview covers the on-prem BIG-IP with a 3-nic example setup. I then discuss the Azure cloud network and cloud components and how that relates to making a BIG-IP work in the Azure cloud. Things discussed include NICs, routes, network security groups, and IP configurations. The important thing to remember is that the cloud is not like on-prem regarding things like L2 and L3 networking components. This makes a difference as you assign NICs and IPs to each virtual machine in the cloud. Read more here on F5 CloudDocs for Azure BIG-IP Deployments. BIG-IP HA and Failover Methods The high availability section will review three different videos. These videos will discuss the failover methods for a BIG-IP cluster and how traffic can failover to the second device upon a failover event. I also discuss IP addressing options for the BIG-IP VIP/listeners and "why". Question: “Which F5 solution is right for me? Autoscaling or HA solutions?” Use these bullet points as guidance: Auto Scale Solution Ramp up/down time to consider as new instances come and go Dynamically adjust instance count based on CPU, memory, and throughput No failover, all devices are Active/Active Self-healing upon device failure (thanks to cloud provider native features) Instances are deployed with 1-NIC only HA Failover (non auto scale) No Ramp up/down time since no additional devices are "auto" scaling No dynamic scaling of the cluster, it will remain as two (2) instances Yes failover, UDRs and IP config will failover to other BIG-IP instance No self-healing, manual maintenance is required by user (similar to on-prem) Instances can be deployed with multiple NICs if needed HA Using API for Failover How do IP addresses and routes failover to the other BIG-IP unit and still process traffic with no layer 2 (L2) networking? Easy, API calls to the cloud. When you deploy an HA pair of BIG-IP instances in the Azure cloud, the BIG-IP instances are onboarded with various cloud scripts. These scripts help facilitate the moving of cloud objects by detecting failover events, triggering API calls to Azure cloud, and thus moving cloud objects (ex. Azure IPs, Azure route next-hops). Traffic now processes successfully on the newly active BIG-IP instance. Benefits of Failover via API: This is most similar to a traditional HA setup No ALB or ILB required VIPs, SNATs, Floating IPs, and managed routes (UDR) can failover to the peer SNAT pool can be used if port exhaustion is a concern SNAT automap is optional (UDR routes needed if SNAT none) Requirements for Failover via API: Service Principal required with correct permissions BIG-IP needs outbound internet access to Azure REST API on port 443 Mutli-NIC required Other things to know: BIG-IP pair will be active/standby Failover times are dependent on Azure API queue (30-90 seconds, sometimes longer) I have experienced up to 20 minutes to failover IPs (public IPs, private IPs) UDR route table entries typically take 5-10 seconds in my testing experience BIG-IP listener can be secondary private IP associated with NIC can be an IP within network prefix being routed to BIG-IP via UDR Read about the F5 GitHub Azure Failover via API templates. HA Using ALB for Failover This type of BIG-IP deployment in Azure requires the use of an Azure load balancer. This ALB sits in a Tier 1 position and acts as an Layer 4 (L4) load balancer to the BIG-IP instances. The ALB performs health checks against the BIG-IP instances with configurable timers. This can result in a much faster failover time than the "HA via API" method in which the latter is dependent on the Azure API queue. In default mode, the ALB has Direct Server Return (DSR) disabled. This means the ALB will DNAT the destination IP requested by the client. This results in the BIG-IP VIP/listener IP listening on a wildcard 0.0.0.0/0 or the NIC subnet range like 10.1.1.0/24. Why? Because ALB will send traffic to the BIG-IP instance on a private IP. This IP will be unique per BIG-IP instance and cannot "float" over without an API call. Remember, no L2...no ARP in the cloud. Rather than create two different listener IP objects for each app, you can simply use a network range listener or a wildcard. The video has a quick example of this using various ports like 0.0.0.0/0:443, 0.0.0.0/0:9443. Benefits of Failover via LB: 3-NIC deployment supports sync-only Active/Active or sync-fail Active/Standby Failover times depend on ALB health probe (ex. 5 sec) Multiple traffic groups are supported Requirements for Failover via LB: ALB and/or ILB required SNAT automap required Other things to know: BIG-IP pair will be active/standby or active/active depending on setup ALB is for internet traffic ILB is for internal traffic ALB has DSR disabled by default Failover times are much quicker than "HA via API" Times are dependent on Azure LB health probe timers Azure LB health probe can be tcp:80 for example (keep it simple) Backend pool members for ALB are the BIG-IP secondary private IPs BIG-IP listener can be wildcard like 0.0.0.0/0 can be network range associated with NIC subnet like 10.1.1.0/24 can use different ports for different apps like 0.0.0.0/0:443, 0.0.0.0/0:9443 Read about the F5 GitHub Azure Failover via ALB templates. HA Using ALB for Failover with DSR Enabled (Floating IP) This is a quick follow up video to the previous "HA via ALB". In this fourth video, I discuss the "HA via ALB" method again but this time the ALB has DSR enabled. Whew! Lots of acronyms! When DSR is enabled, the ALB will send the traffic to the backend pool (aka BIG-IP instances) private IP without performing destination NAT (DNAT). This means...if client requested 2.2.2.2, then the ALB will send a request to the backend pool (BIG-IP) on same destination 2.2.2.2. As a result, the BIG-IP VIP/listener will match the public IP on the ALB. This makes use of a floating IP. Benefits of Failover via LB with ALB DSR Enabled: Reduces configuration complexity between the ALB and BIG-IP The IP you see on the ALB will be the same IP as the BIG-IP listener Failover times depend on ALB health probe (ex. 5 sec) Requirements for Failover via LB: DSR enabled on the Azure ALB or ILB ALB and/or ILB required SNAT automap required Dummy VIP "healthprobe" to check status of BIG-IP on individual self IP of each instance Create one "healthprobe" listener for each BIG-IP (total of 2) VIP listener IP #1 will be BIG-IP #1 self IP of external network VIP listener IP #2 will be BIG-IP #2 self IP of external network VIP listener port can be 8888 for example (this should match on the ALB health probe side) attach iRule to listener for up/down status Example iRule... when HTTP_REQUEST { HTTP::respond 200 content "OK" } Other things to know: ALB is for internet traffic ILB is for internal traffic BIG-IP pair will operate as active/active Failover times are much quicker than "HA via API" Times are dependent on Azure LB health probe timers Backend pool members for ALB are the BIG-IP primary private IPs BIG-IP listener can be same IP as the ALB public IP can use different ports for different apps like 2.2.2.2:443, 2.2.2.2:8443 Read about the F5 GitHub Azure Failover via ALB templates. Also read about Azure LB and DSR. Auto Scale BIG-IP with ALB This type of BIG-IP deployment takes advantage of the native cloud features by creating an auto scaling group of BIG-IP instances. Similar to the "HA via LB" mentioned earlier, this deployment makes use of an ALB that sits in a Tier 1 position and acts as a Layer 4 (L4) load balancer to the BIG-IP instances. Azure auto scaling is accomplished by using Azure Virtual Machine Scale Sets that automatically increase or decrease BIG-IP instance count. Benefits of Auto Scale with LB: Dynamically increase/decrease BIG-IP instance count based on CPU and throughput If using F5 auto scale WAF templates, then those come with pre-configured WAF policies F5 devices will self-heal (cloud VM scale set will replace damaged instances with new) Requirements for Auto Scale with LB: Service Principal required with correct permissions BIG-IP needs outbound internet access to Azure REST API on port 443 ALB required SNAT automap required Other things to know: BIG-IP cluster will be active/active BIG-IP will be deployed with 1-NIC BIG-IP onboarding time BIG-IP VE process takes about 3-8 minutes depending on instance type and modules Azure VM Scale Set configured with 10 minute window for scale up/down window (ex. to prevent flapping) Take these timers into account when looking at full readiness to accept traffic BIG-IP listener can be wildcard like 0.0.0.0/0 can use different ports for different apps like 0.0.0.0/0:443, 0.0.0.0/0:9443 Licensing PAYG marketplace licensing can be used BIG-IQ license manager can be used for BYOL licensing Sorry, no video yet...a picture will have to do! Here's an example diagram of auto scale with ALB. Read about the F5 GitHub Azure Auto Scale via ALB templates. Auto Scale BIG-IP with DNS This type of BIG-IP deployment takes advantage of the native cloud features by creating an auto scaling group of BIG-IP instances. Unlike "HA via LB" mentioned earlier or "Auto Scale with ALB", this deployment makes use of DNS that acts as a method to distribute traffic to the auto scaling BIG-IP instances. This solution integrates with F5 BIG-IP DNS (formerly named GTM). And...since there is no ALB in front of the BIG-IP instances, this means you do not need SNAT automap on the BIG-IP listeners. In other words, if you have apps that need to see the real client IP and they are non-HTTP apps (can't pass XFF header) then this is one method to consider. Benefits of Auto Scale with DNS: Dynamically increase/decrease BIG-IP instance count based on CPU and throughput If using F5 auto scale WAF templates, then those come with pre-configured WAF policies F5 devices will self-heal (cloud VM scale set will replace damaged instances with new) ALB not required (cost savings) SNAT automap not required Requirements for Auto Scale with DNS: Service Principal required with correct permissions BIG-IP needs outbound internet access to Azure REST API on port 443 SNAT automap optional BIG-IP DNS (aka GTM) needs connectivity to each BIG-IP auto scaled instance Other things to know: BIG-IP cluster will be active/active BIG-IP will be deployed with 1-NIC BIG-IP onboarding time BIG-IP VE process takes about 3-8 minutes depending on instance type and modules Azure VM Scale Set configured with 10 minute window for scale up/down window (ex. to prevent flapping) Take these timers into account when looking at full readiness to accept traffic BIG-IP listener can be wildcard like 0.0.0.0/0 can use different ports for different apps like 0.0.0.0/0:443, 0.0.0.0/0:9443 Licensing PAYG marketplace licensing can be used BIG-IQ license manager can be used for BYOL licensing Sorry, no video yet...a picture will have to do! Here's an example diagram of auto scale with DNS. Read about the F5 GitHub Azure Auto Scale via DNS templates. Summary That's it for now! I hope you enjoyed the video series (here in full on YouTube) and quick explanation. Please leave a comment if this helped or if you have additional questions. Additional Resources F5 High Availability - Public Cloud Guidance The Hitchhiker’s Guide to BIG-IP in Azure The Hitchhiker’s Guide to BIG-IP in Azure – “Deployment Scenarios” The Hitchhiker’s Guide to BIG-IP in Azure – “High Availability” The Hitchhiker’s Guide to BIG-IP in Azure – “Life Cycle Management”8.9KViews7likes7CommentsConfigure HA Groups on BIG-IP
Last week we talked about how HA Groups work on BIG-IP and this week we’ll look at how to configure HA Groupson BIG-IP. To recap, an HA group is a configuration object you create and assign to a traffic group for devices in a device group. An HA group defines health criteria for a resource (such as an application server pool) that the traffic group uses. With an HA group, the BIG-IP system can decide whether to keep a traffic group active on its current device or fail over the traffic group to another device when resources such as pool members fall below a certain level. First, some prerequisites: Basic Setup: Each BIG-IP (v13) is licensed, provisioned and configured to run BIG-IP LTM HA Configuration: All BIG-IP devices are members of a sync-failover device group and synced Each BIG-IP has a unique virtual server with a unique server pool assigned to it All virtual addresses are associated with traffic-group-1 To the BIG-IP GUI! First you go to System>High Availability>HA Group List>and then click the Create button. The first thing is to name the group. Give it a detailed name to indicate the object group type, the device it pertains to and the traffic group it pertains to. In this case, we’ll call it ‘ha_group_deviceA_tg1.’ Next, we’ll click Add in the Pools area under Health Conditions and add the pool for BIG-IP A to the HA Group which we’ve already created. We then move on to the minimum member count. The minimum member count is members that need to be up for traffic-group-1 to remain active on BIG-IP A. In this case, we want 3 out of 4 members to be up. If that number falls below 3, the BIG-IP will automatically fail the traffic group over to another device in the device group. Next is HA Score and this is the sufficient threshold which is the number of up pool members you want to represent a full health score. In this case, we’ll choose 4. So if 4 pool members are up then it is considered to have a full health score. If fewer than 4 members are up, then this health score would be lower. We’ll give it a default weight of 10 since 10 represents the full HA score for BIG-IP A. We’re going to say that all 4 members need to be active in the group in order for BIG-IP to give BIG-IP A an HA score of 10. And we click Add. We’ll then see a summary of the health conditions we just specified including the minimum member count and sufficient member count. Then click Create HA Group. Next, we go to Device Management>Traffic Groups>and click on traffic-group-1. Now, we’ll associate this new HA Group with traffic-group-1. Go to the HA Group setting and select the new HA Group from the drop-down list. And then select the Failover Method to Device with the Best HA Score. Click Save. Now we do the same thing for BIG-IP B. So again, go to System>High Availability>HA Group List>and then click the Create button. Give it a special name, click Add in the Pools area and select the pool you’ve already created for BIG-IP B. Again, for our situation, we’ll specify a minimum of 3 members to be up if traffic-group-1 is active on BIG-IP B. This minimum number does not have to be the same as the other HA Group, but it is for this example. Again, a default weight of 10 in the HA Score for all pool members. Click Add and then Create HA Group for BIG-IP B. And then, Device Management>Traffic Groups> and click traffic-group-1. Choose BIG-IP B’s HA Group and select the same Failover method as BIG-IP A – Based on HA Score. Click Save. Lastly, you would create another HA Group on BIG-IP C as we’ve done on BIG-IP A and BIG-IP B. Once that happens, you’ll have the same set up as this: As you can see, BIG-IP A has lost another pool member causing traffic-group-1 to failover and the BIG-IP software has chosen BIG-IP C as the next active device to host the traffic group because BIG-IP C has the highest HA Score based on the health of its pool. Thanks to our TechPubs group for the basis of this article and check out a video demo here. ps8.7KViews1like0CommentsCreate a BIG-IP HA Pair in Azure
Use an Azure ARM template to create a high availability (active-standby) pair of BIG-IP Virtual Edition instances in Microsoft Azure. When one BIG-IP VE goes standby, the other becomes active, the virtual server address is reassigned from one external NIC to another. Today, let’s walk through how to create a high availability pair of BIG-IP VE instances in Microsoft Azure. When we’re done, we’ll have an active-standby pair of BIG-IP VEs. To start, go to the F5 Networks Github repository. Click F5-azure-arm-templates. Then go to Supported>failover. You have several options at this point. You can chose which templates to use based on your needs, failing over via API calls, via upstream load balancers, and NIC counts. Read each readme to determine your desired deployment strategy. When you already have your subnets and existing IP addresses defined but to see how it works, let’s deploy a new stack. Click new stack and scroll down to the Deploy button. If you have a trial or production license from F5, you can use the BYOL or BIG-IQ as license server options but in this case we’re going to choose the PAYG option. Click Deploy and the template opens in the Azure portal. Now we simply fill out the fields. We’ll create a new Resource Group and set a password for the BIG-IP VEs. When you get to the questions: The DNS label is used as part of the URL. Instance Name is just the name of the VM in Azure. Instance Type determines how much memory and CPU you’ll have. Image Name determines how many BIG-IP modules you can run (and you can choose the latest BIG-IP version). Licensed Bandwidth determines the maximum throughput of the traffic going through BIG-IP. Select the Number of External IP addresses (we’ll start with one but can add more later). For instance, if you plan on running more than one application behind the BIG-IP, then you’ll need the appropriate external IP addresses. Vnet Address Prefix is for the address ranges of you subnets (we’ll leave at default). The next 3 fields (Tenant ID, Client ID, Service Principal Secret) have to do with security. Rather than using your own credentials to modify resources in Azure, you can create an Active Directory application and assign permissions to it. The last two fields also go together. Managed Routes let you route traffic from other external networks through the BIG-IPs. The Route Table Tag means that anytime this tag is found in the route table, routes that have this destination are updated so that the next hop is the IP address of the active BIG-IP VE. This is useful if you want all outbound traffic to go through the BIG-IP or if you want to send traffic from a bunch of different Vnets through the BIG-IP. We’ll leave the rest as default but the Restricted Src Address is good way to put IP addresses on my network – the ones that are allowed to connect to the BIG-IP. We’ll agree to the terms and click Purchase. We’re redirected to the Dashboard with the Deployment in Progress indicator. This takes about 15 minutes. Once finished we’ll go check all the resources in the Resource Group. Let’s find out where the virtual server address is located since this is associated with one of the external NICs, which have ‘ext’ in the name. Click the one you want. Then click IP Configuration under Settings. When you look at the IP Configuration for these NICs, whenever the NIC has two IP addresses that’s the NIC for the active BIG-IP. The Primary IP address is the BIG-IP Self IP and the Secondary IP is the virtual server address. If we look at the other external NIC we’ll see that it only has one Self IP and that’s the Primary and it doesn’t have the Secondary virtual server address. The virtual server address is assigned to the active BIG-IP. When we force the active BIG-IP to standby, the virtual server address is reassigned from one NIC to the other. To see this, we’ll log into the BIG-IPs and on the active BIG-IP, we’ll click Force to Standby and the other BIG-IP becomes Active. When we go back to Azure, we can see that the virtual server IP is no longer associated with the external NIC. And if we wait a few minutes, we’ll see that the address is now associated with the other NIC. So basically how BIG-IP HA works in the Azure cloud is by reassigning the virtual server address from one BIG-IP to another. Thanks to our TechPubs group and check out the demo video. ps6.1KViews0likes5Comments
Client-side vs Server-side Load Balancing
Lei Zhu @ Digital Web Magazine has an interesting article on Client Side Load Balancing for Web 2.0 Applications. It is interesting in that it presents an alternative mechanism for implementing high-availability without the use of an intermediate load balancing solution. His solution relies solely on the client and takes advantage of the dynamic nature of Web 2.0. The problem with Lei's article is that there are a few assumptions made that are simply inaccurate. Leicontends that the negatives to using an intermediate load balancing solution are: There is a limit to the number of requests the load balancer itself can handle. However, this problem can be resolved with the combination of round-robin DNS and dedicated load balancers. The upper bounds of a hardware load balancing solution are typically higher than any given server can handle. We are talking about hundreds of thousands of requests per second. Round-robin DNS, whilean industry standard, isone of the most rudimentary implementations of "load balancing" that exists. Load balancers, a.k.a. application delivery controllers, today are capable of making routing decisions based on much more intelligent factors than a simple list of servers. There is no server that can handle more requests than a load balancing solution today. Even SMB load balancers can process requests faster than any server and maintain a session table muchlarger than existing web and application servers. There is an extra cost related to operating a dedicated load balancer, which can run into tens of thousands of dollars. The backup load balancer generally does nothing other than wait for the primary to fail. It is absolutely true that an intermediate load balancer is going to require an investment. That the backup "does nothing" is entirely dependent upon the implementation. Load balancers today are capable of both active-standby (this is Lei's assumption here) as well as active-active configurations. In an active-active configuration both load balancers are working all the time. It is completely up to the implementor to determine which configuration should be used. Lei also claims: It is easier to make the client code and resources highly available and scalable than to do so for the servers—serving non-dynamic content requires fewer server resources. There are two statements here, one regarding the ease with which you can deploy a highly available site and that serving non-dynamic content requires fewer server resources. The latter is absolutely correct, it does indeed take less resources on the server to serve non-dynamic content. The former assertion, however, is not entirely true. Lei's article describes a methodology that requires modifications to not only the application (the client code) but also to the infrastructure (additional servers and entries in DNS to accomodate the new servers). A good application delivery controller will not require changes to the application and will be less disruptive to the infrastructure because it effectively intercepts requests for the domain and handles them without changes to the server-side of the equation. For example, if your domain is www.example.comand you implement a load balancing solution, the load balancer becomes www.example.com. Servers can be added to the pool (a.k.a. cluster, farm) of servers and it will then distribute requests amongst those servers without any further changes to the client or the servers. A good application delivery controller can distribute requests based on more than DNS round-robin algorithms, and can base its decisions in real time on the health and status of any given server. This is one the problems with Lei's arguments - he bases his decision upon a single, outdated mechanism for load balancing and uses that as the basis for recommending a client-side solution. And as far as scalability - let's look at that for a moment. In the intermediate load balancer scenario if we need more resources we (1) add another server,and (2) add it to the pool on the load balancer.In Lei's scenario we (1) add another server, (2) reconfigure the client-application, and (3) add another entry to DNS. Lei's solution is much more invasive and disruptive to every piece of the equation than the intermediate load balancing solution scenario, and Lei's solution is not guaranteed to work as he cannot ensure that the client browser's caching scheme will definitively update and include the new server. And lest we forget, Lei does not discuss the problem of persistence inherent in his client-side solution. A purely round-robin based solution that ignores client-session is limited in use and value. The solution must take into consideration the possibility that a client needs to be tied to a particular server for the duration of a session. This is particularly true of e-commerce sites. A client-side solution that does not take this into consideration (and Lei's solution does not) will not be useful in many situations. A good application delivery controller by default is capable of handling persistence and "stickiness" to a server - and again does so without requiring modification to the client or server side code. Lei's client-side load balancing solution is novel, and while it certainly might be interesting for individual developers whose livelihoods do not rely on the availability of their site this solution is not something that should be recommended lightly and without a great deal of forethought. The assumptions upon which his article is based are, with the exception the additional cost of a load balancing solution, outdated and inaccurate. Client-side load balancing requires more maintenance, more initial work to deploy, and introduces security risks by "opening the organization's kimono" and showing clients what lies beneath, namely the infrastructure architecture. Imbibing: Coffee Technorati tags: MacVittie, F5, load balancing, application delivery, scalability, high availability, Web 2.02.3KViews0likes1CommentHigh Availability Groups on BIG-IP
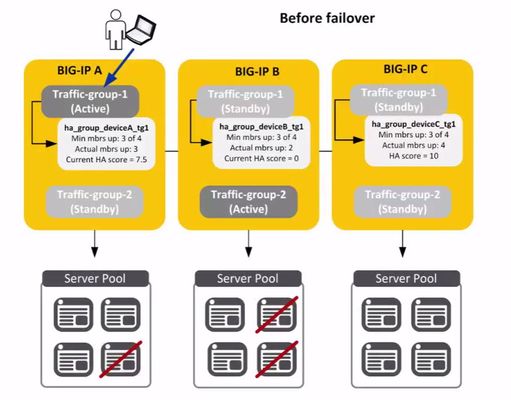
High Availability of applications is critical to an organization’s survival. On BIG-IP, HA Groups is a feature that allows BIG-IP to fail over automatically based not on the health of the BIG-IP system itself but rather on the health of external resources within a traffic group. These external resources include the health and availability of pool members, trunk links, VIPRION cluster members or a combination of all three. This is the only cause of failover that is triggered based on resources outside of the BIG-IP. An HA group is a configuration object you create and assign to a traffic group for devices in a device group. An HA group defines health criteria for a resource (such as an application server pool) that the traffic group uses. With an HA group, the BIG-IP system can decide whether to keep a traffic group active on its current device or fail over the traffic group to another device when resources such as pool members fall below a certain level. In this scenario, there are three BIG-IP Devices – A, B, C and each device has two traffic groups on it. As you can see, for BIG-IP A, traffic-group 1 is active. For BIG-IP B, traffic-group 2 is active and for BIG-IP C, both traffic groups are in a standby state. Attached to traffic-group 1 on BIG-IP A is an HA group which specifies that there needs to be a minimum of 3 pool members out of 4 to be up for traffic-group-1 to remain active on BIG-IP A. Similarly, on BIG-IP B the traffic-group needs a minimum of 3 pool members up out of 4 for this traffic group to stay active on BIG-IP B. On BIG-IP A, if fewer than 3 members of traffic-group-1 are up, this traffic-group will fail-over. So let’s say that 2 pool members go down on BIG-IP A. Traffic-group-1 responds by failing-over to the device (BIG-IP) that has the healthiest pool…which in this case is BIG-IP C. Now we see that traffic-group-1 is active on BIG-IP C. Achieving the ultimate ‘Five Nines’ of web site availability (around 5 minutes of downtime a year) has been a goal of many organizations since the beginning of the internet era. There are several ways to accomplish this but essentially a few principles apply. Eliminate single points of failure by adding redundancy so if one component fails, the entire system still works. Have reliable crossover to the duplicate systems so they are ready when needed. And have the ability to detect failures as they occur so proper action can be taken. If the first two are in place, hopefully you never see a failure. But if you do, HA Groups can help. ps Related: Lightboard Lessons: BIG-IP Basic Nomenclature Lightboard Lessons: Device Services Clustering HA Groups Overview2.2KViews0likes2Comments
High Availability - functions well, however peer device shows offline.
Hello Folks, I have 2 LTM deployed in HA, running over firmware version 11.2.0 However, one of the devices shows offline status in peer list. At the same time the device is in Sync, failover works well too. However in peer list of Primary device, I can see secondary appliance as offline. Anyone had experience similar issues before? What could be the possible and feasible solution? Regards, DarshanSolved1.1KViews0likes13Comments
High-availability configuration produces a status of "ONLINE (STANDBY), In Sync"
Problem: High-availability configuration produces a status of "ONLINE (STANDBY), In Sync" on the F5 primary and standby units. Models: F5 1600 Big-IP Version: BIG-IP 11.5.0 Build 7.0.265 Hotfix HF7 Steps used to configure high-availability: Connect a network cable on port 1.3 of each F5 1600 Create a dedicated VLAN for high-availability on each F5 1600 Configure an IP address for the high-availability VLAN on each F5 1600 Ensure that both F5 1600 units can ping each other from the high-availability VLAN On each F5 1600, navigate to "Device Management" -> "Devices" -> "Device List". Select the F5 1600 system labelled as "self" On each F5 1600, navigate to "Device Connectivity" -> "ConfigSync". Select the IP address assigned to the high-availability VLAN On each F5 1600, navigate to "Device Connectivity" -> "Network Failover". Add the IP address assigned to the high-availability VLAN to the failover unicast configuration Force the standby unit offline On the active unit, navigate to "Device" -> "Peer List". Click "Add", and add standby unit to the high-availability configuration At this point, the primary F5 unit has a status of "ONLINE (ACTIVE), In Sync", and the standby unit has a status of "FORCED (OFFLINE), In Sync" On the primary unit, navigate to "Device Management" -> "Device Groups" to create a device group At this point, both units have a status of "ONLINE (STANDBY), In Sync". Any ideas as to why this happening? My goal is to have high-availability configured in an ACTIVE/STANDBY pair.1KViews0likes15CommentsWhy is an Active-Active configuration not recommended by F5?
I was considering configuring our F5 LTMs in an Active/Active state within Cisco ACI but I read here that this type of configuration is not recommended without having at least one F5 in standby mode. "F5 does not recommend deploying BIP-IP systems in an Active-Active configuration without a standby device in the cluster, due to potential loss of high availability." Why is this? With two F5s in Active/Active mode, they should still fail over to each other if one happens to go down. Would it take longer for one device to fail over to another who is active rather than being truly standby?899Views0likes5CommentsBIG-IQ HA inquiry
Hi, Just want to ask for assistance if below plan of deployment is possible. DC 1 - 1 x BIG-IQ VE DC 2 - 1 x BIG-IQ VE Then both BIG-IQ VE will be in HA setup. Is this possible? The reason why we go to this approach so that when 1 DC goes down we still have BIG-IQ in DC2. Hoping for your advise based on your experience if you already do this approach. Thanks.Solved701Views0likes3CommentsFailover object missing in traffic group
Hello Folks, When we cannot see an object within failover objects and how to add it manually? I have a VS, which isn't appearing in Failover objects. And strange thing is, for that specific VS, traffic goes to standby appliance and that is actually processes the traffic. As a result the VS servers intermittent services and looses the connection and functionality anytime. I have tried creating a new VS, however that behaves the same way. And again that VS is not reflecting to failover objects. Any clues? Thanks, Darshan490Views0likes14Comments