Devops Proverb: Process Practice Makes Perfect
#devops Tools for automating – and optimizing – processes are a must-have for enabling continuous delivery of application deployments Some idioms are cross-cultural and cross-temporal. They transcend cultures and time, remaining relevant no matter where or when they are spoken. These idioms are often referred to as proverbs, which carries with it a sense of enduring wisdom. One such idiom, “practice makes perfect”, can be found in just about every culture in some form. In Chinese, for example, the idiom is apparently properly read as “familiarity through doing creates high proficiency”, i.e. practice makes perfect. This is a central tenet of devops, particularly where optimization of operational processes is concerned. The more often you execute a process, the more likely you are to get better at it and discover what activities (steps) within that process may need tweaking or changes or improvements. Ergo, optimization. This tenet grows out of the agile methodology adopted by devops: application release cycles should be nearly continuous, with both developers and operations iterating over the same process – develop, test, deploy – with a high level of frequency. Eventually (one hopes) we achieve process perfection – or at least what we might call process perfection: repeatable, consistent deployment success. It is implied that in order to achieve this many processes will be automated, once we have discovered and defined them in such a way as to enable them to be automated. But how does one automate a process such as an application release cycle? Business Process Management (BPM) works well for automating business workflows; such systems include adapters and plug-ins that allow communication between systems as well as people. But these systems are not designed for operations; there are no web servers or databases or Load balancer adapters for even the most widely adopted BPM systems. One such solution can be found in Electric Cloud with its recently announced ElectricDeploy. Process Automation for Operations ElectricDeploy is built upon a more well known product from Electric Cloud (well, more well-known in developer circles, at least) known as ElectricCommander, a build-test-deploy application deployment system. Its interface presents applications in terms of tiers – but extends beyond the traditional three-tiers associated with development to include infrastructure services such as – you guessed it – load balancers (yes, including BIG-IP) and virtual infrastructure. The view enables operators to create the tiers appropriate to applications and then orchestrate deployment processes through fairly predictable phases – test, QA, pre-production and production. What’s hawesome about the tools is the ability to control the process – to rollback, to restore, and even debug. The debugging capabilities enable operators to stop at specified tasks in order to examine output from systems, check log files, etc..to ensure the process is executing properly. While it’s not able to perform “step into” debugging (stepping into the configuration of the load balancer, for example, and manually executing line by line changes) it can perform what developers know as “step over” debugging, which means you can step through a process at the highest layer and pause at break points, but you can’t yet dive into the actual task. Still, the ability to pause an executing process and examine output, as well as rollback or restore specific process versions (yes, it versions the processes as well, just as you’d expect) would certainly be a boon to operations in the quest to adopt tools and methodologies from development that can aid them in improving time and consistency of deployments. The tool also enables operations to determine what is failure during a deployment. For example, you may want to stop and rollback the deployment when a server fails to launch if your deployment only comprises 2 or 3 servers, but when it comprises 1000s it may be acceptable that a few fail to launch. Success and failure of individual tasks as well as the overall process are defined by the organization and allow for flexibility. This is more than just automation, it’s managed automation; it’s agile in action; it’s focusing on the processes, not the plumbing. MANUAL still RULES Electric Cloud recently (June 2012) conducted a survey on the “state of application deployments today” and found some not unexpected but still frustrating results including that 75% of application deployments are still performed manually or with little to no automation. While automation may not be the goal of devops, but it is a tool enabling operations to achieve its goals and thus it should be more broadly considered as standard operating procedure to automate as much of the deployment process as possible. This is particularly true when operations fully adopts not only the premise of devops but the conclusion resulting from its agile roots. Tighter, faster, more frequent release cycles necessarily puts an additional burden on operations to execute the same processes over and over again. Trying to manually accomplish this may be setting operations up for failure and leave operations focused more on simply going through the motions and getting the application into production successfully than on streamlining and optimizing the processes they are executing. Electric Cloud’s ElectricDeploy is one of the ways in which process optimization can be achieved, and justifies its purchase by operations by promising to enable better control over application deployment processes across development and infrastructure. Devops is a Verb 1024 Words: The Devops Butterfly Effect Devops is Not All About Automation Application Security is a Stack Capacity in the Cloud: Concurrency versus Connections Ecosystems are Always in Flux The Pythagorean Theorem of Operational Risk246Views0likes1CommentInside Look - PCoIP Proxy for VMware Horizon View
I sit down with F5 Solution Architect Paul Pindell to get an inside look at BIG-IP's native support for VMware's PCoIP protocol. He reviews the architecture, business value and gives a great demo on how to configure BIG-IP. BIG-IP APM offers full proxy support for PC-over-IP (PCoIP), a leading virtual desktop infrastructure (VDI) protocol. F5 is the first to provide this functionality which allows organizations to simplify their VMware Horizon View architectures. Combining PCoIP proxy with the power of the BIG-IP platform delivers hardened security and increased scalability for end-user computing. In addition to PCoIP, F5 supports a number of other VDI solutions, giving customers flexibility in designing and deploying their network infrastructure. ps Related: F5 Friday: Simple, Scalable and Secure PCoIP for VMware Horizon View Solutions for VMware applications F5's YouTube Channel In 5 Minutes or Less Series (24 videos – over 2 hours of In 5 Fun) Inside Look Series Life@F5 Series Technorati Tags: vdi,PCoIP,VMware,Access,Applications,Infrastructure,Performance,Security,Virtualization,silva,video,inside look,big-ip,apm Connect with Peter: Connect with F5:345Views0likes0CommentsThe all new iRules Wiki brings you enhanced documentation and more!
Editors note: The iRules Wiki moved to F5's CloudDocs platform in May of 2019. iRules Home (f5.com) DevCentral is all about enabling users in the community to do powerful and innovative things. Whether it’s providing answers to your technical questions in the Forums, giving you the latest up to date news about F5, or providing documentation on some of the coolest things F5 has to offer, like iRules and iControl, we do our best to keep you up to speed, and equipped to get the most out of your F5 devices. With that in mind, we’ve been working hard to heed the call from the members of the community, partners, and the entire F5 global team for extended and enhanced documentation about iRules. Well we’re quite happy to announce the DevCentral iRules Wiki! - http://clouddocs.f5.com/api/irules/. This new section of DevCentral, intended to be a constant work in progress, represents the most comprehensive, advanced documentation of the iRules language available to date. Whether you’re just getting started, or you’re, there’s something there for everyone. And regardless of your skill level, the CodeShare is sure to have some cool examples of what you can do, and what others are currently doing with iRules. It’s also a place to share your cool ideas with others! Why? Well, the more people share, the more likely you’ll be able to find the perfect iRule sample when you need it most at some point in the future. By working together, the community can benefit from the collective experience contributed by all members. Our real goal in providing this sort of documentation, though, is to provide the tools you need to truly leverage F5’s solutions in your environment. That’s what this Wiki is all about. With this addition we hope to: Offer additional resources beyond the Forums for iRule information. We love talking to you in the Forums, but sometimes you just want the facts, fast. Provide enhanced documentation in a centralized location. We want to make it easier to find more of what you want, when you want it. Increase your success with iRules by enabling you to find what you need to succeed.The better we can make you look, the happier we are…seriously. So check it out, poke around, and let us know what you think. We’re constantly striving to make this a better place for you to come together to learn, discuss and share, whether it’s about iRules or any of the other things happening on DevCentral so feedback is always welcome.1.1KViews0likes1Comment
Installing LTM VE on VMWare ESXi
We’ve had a few requests for a tutorial detailing the installation of F5’s new Local Traffic Manager Virtual Edition on VMWare vSphere Hypervisor (ESXi). Now we have one, sort of. We decided the best way to do it was to record it as a video tutorial. If you can stand my stuttering for ten minutes, you should have a working LTM VE instance in no time. First things first, you’ll need to get ESXi up and running before you can move on to the LTM VE portion. We’re not the experts on ESXi, so I thought it best to hand this over to VMWare. Their documentation and hardware compatibility guides can be found here. You’ll need to set up a free account with VMWare and download ESXi here. Once you’ve installed ESXi, you’ve got the vSphere Client up and connected to ESXi, you’re ready to proceed with the LTM VE installation. Watch the video below (switch to HD in order to read the text) for a walkthrough of the LTM VE install: At the completion of this procedure, you should have a fully functional LTM VE instance. You may run into a few snags depending on how your network interfaces are configured, but we’ve got you covered. Jason did a fantastic job of detailing how ESXi networks are configured in this blog post. Spend the time to read the post, it will be well worth your time and will explain many of the nuances of configuring ESXi’s networks. We hope you enjoyed this video tutorial and it helps you get LTM VE running in your environment. Be sure and stop by our F5/VMWare Solutions forum for more dialog on F5 and VMWare integration.267Views0likes1CommentX-Forwarded-For HTTP Module For IIS7, Source Included!
For those who of you that are having problems with logging client addresses in their server logs because you are running your web servers behind a proxy of some sort, never fear, your solution is here. For those that don't, I already discussed in my previous posts about what the X-Forwarded-For header is so feel free to click back into those to read about it. History Back in September, 2005 I wrote and posted a 32-bit ISAPI filter that extracted the X-Forwarded-For header value and replaced the c-ip value (client ip) that is stored in the server logs. Lots of folks have found this useful over time and I was eventually asked for a 64-bit version which I posted about in August, 2009. The Question Well, it looks like it's time for the next generation for this filter… I received an email from a colleague here at F5 telling me that his customer didn't want to deploy any more ISAPI filters in their IIS7 infrastructure. IIS7 introduced the concept of IIS Modules that are more integrated into the whole pipeline and was told that Microsoft is recommending folks move in that direction. I was asked if I had plans to port my ISAPI filter into a HTTP Module. The Answer Well, the answer was "probably not", but now it's changed to a "yes"! The Solution In reading about IIS Module, I found that you can develop in managed (C#/VB) or Native (C++) code. I loaded up the test C# project to see if I could get it working. In a matter of minutes I had a working module that intercepted the event when logging occurs. The only problem was that from managed code, I could find no way to actually modify the values that were passed to the logging processor. This was a problem so I scrapped that and moved to a native C++ module. After a little while of jumping through the documentation, I found the things I needed and pretty soon I had a working HTTP module that implemented the same functionality as the ISAPI filter. Download The new Http Module hasn't had much testing done so please test it out before you roll it out into production. I've made the source available as well if you find an issue and care to fix it. Just make sure you pass back the fixes to me B-). X-Forwarded-For Http Module Binary Distribution X-Forwarded-For Http Module Source Distribution The filter will require installation into IIS in order for you to be able to add it to your applications. Both distributions include a readme.txt file with an example installation procedure. Make sure you use the Release builds for the appropriate platform (x86 or x64) unless you are in need of some troubleshooting as the Debug build will dump a lot of data to a log file. The module supports customizable headers if you are using something other than X-Forwarded-For. Instructions for using that are in the readme.txt file as well. If you have any issues with using this, please let me know on this blog. Keep in mind that this is an unsupported product, but I'll do my best to fix any issues that come up. I'm even open to enhancements if you can think of any. Enjoy! -Joe3.4KViews0likes23CommentsX-Forwarded-For Log Filter for Windows Servers
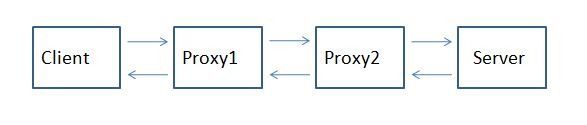
For those that don't know what X-Forwarded-For is, then you might as well close your browser because this post likely will mean nothing to you… A Little Background Now, if you are still reading this, then you likely are having issues with determining the origin client connections to your web servers. When web requests are passed through proxies, load balancers, application delivery controllers, etc, the client no longer has a direct connection with the destination server and all traffic looks like it's coming from the last server in the chain. In the following diagram, Proxy2 is the last hop in the chain before the request hits the destination server. Relying on connection information alone, the server thinks that all connections come from Proxy2, not from the Client that initiated the connection. The only one in the chain here who knows who the client really is (as determined by it's client IP Address, is Proxy1. The problem is that application owners rely on source client information for many reasons ranging from analyzing client demographics to targeting Denial of Service attacks. That's where the X-Forwarded-For header comes in. It is non-RFC standard HTTP request header that is used for identifying the originating IP address of a client connecting to a web server through a proxy. The format of the header is: X-Forwarded-For: client, proxy1, proxy, … X-Forwarded-For header logging is supported in Apache (with mod_proxy) but Microsoft IIS does not have a direct way to support the translation of the X-Forwarded-For value into the client ip (c-ip) header value used in its webserver logging. Back in September, 2005 I wrote an ISAPI filter that can be installed within IIS to perform this transition. This was primarily for F5 customers but I figured that I might as well release it into the wild as others would find value out of it. Recently folks have asked for 64 bit versions (especially with the release of Windows 2008 Server). This gave me the opportunity to brush up on my C skills. In addition to building targets for 64 bit windows, I went ahead and added a few new features that have been asked for. Proxy Chain Support The original implementation did not correctly parse the "client, proxy1, proxy2,…" format and assumed that there was a single IP address following the X-Forwarded-For header. I've added code to tokenize the values and strip out all but the first token in the comma delimited chain for inclusion in the logs. Header Name Override Others have asked to be able to change the header name that the filter looked for from "X-Forwarded-For" to some customized value. In some cases they were using the X-Forwarded-For header for another reason and wanted to use iRules to create a new header that was to be used in the logs. I implemented this by adding a configuration file option for the filter. The filter will look for a file named F5XForwardedFor.ini in the same directory as the filter with the following format: [SETTINGS] HEADER=Alternate-Header-Name The value of "Alternate-Header-Name" can be changed to whatever header you would like to use. Download I've updated the original distribution file so that folks hitting my previous blog post would get the updates. The following zip file includes 32 and 64 bit release versions of the F5XForwardedFor.dll that you can install under IIS6 or IIS7. Installation Follow these steps to install the filter. Download and unzip the F5XForwardedFor.zip distribution. Copy the F5XForwardedFor.dll file from the x86\Release or x64\Release directory (depending on your platform) into a target directory on your system. Let's say C:\ISAPIFilters. Ensure that the containing directory and the F5XForwardedFor.dll file have read permissions by the IIS process. It's easiest to just give full read access to everyone. Open the IIS Admin utility and navigate to the web server you would like to apply it to. For IIS6, Right click on your web server and select Properties. Then select the "ISAPI Filters" tab. From there click the "Add" button and enter "F5XForwardedFor" for the Name and the path to the file "c:\ISAPIFilters\F5XForwardedFor.dll" to the Executable field and click OK enough times to exit the property dialogs. At this point the filter should be working for you. You can go back into the property dialog to determine whether the filter is active or an error occurred. For II7, you'll want to select your website and then double click on the "ISAPI Filters" icon that shows up in the Features View. In the Actions Pane on the right select the "Add" link and enter "F5XForwardedFor" for the name and "C:\ISAPIFilters\F5XForwardedFor.dll" for the Executable. Click OK and you are set to go. I'd love to hear feedback on this and if there are any other feature request, I'm wide open to suggestions. The source code is included in the download distribution so if you make any changes yourself, let me know! Good luck and happy filtering! -Joe13KViews0likes14CommentsOracle RAC Connection String Rewrite
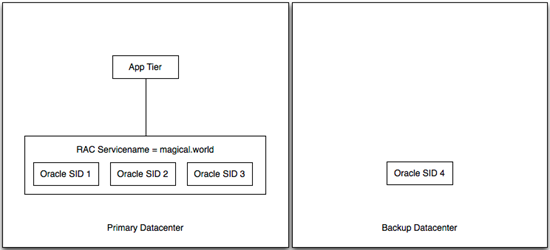
My buddy Brent Imhoff is back with another excellent customer solution to follow up his IPS traffic inspection solution. This solution is a modification of the original iRule for db context switching from the deployment guide for Oracle Database and RAC. Problem Description Customer has two Oracle instances, one in a primary datacenter and one in the secondary datacenter. The primary datacenter is comprised of three Oracle instances, each with a unique Oracle System ID (SID), as part of an Oracle Real Application Cluster (RAC). The secondary datacenter is setup as a single node with it's own SID. The RAC is essentially a load balancer for Oracle nodes, but somewhat limited in that it doesn't work between data centers. As part of the RAC implementation, a Service Name is defined in the RAC configuration and clients use the service name in the connect string. RAC evaluates the service name and makes a determination regarding which SID could handle the request appropriately. Alternatively, clients can use the SID to connect directly to an Oracle node. The customer has some 800 applications that rely on these databases. Because there is RAC only in one location, they are forced to change connect strings each time they need to change the data sources for things like maintenance. Additionally, it removes the possibility of an automated failover if something goes wrong unexpectedly. The customer asked F5 if we could be an Oracle proxy to handle the rewrite of connect strings and essentially make the clients unaware of any changes that might be happening to the Oracle nodes. Old and Busted (aka Oh Crap! My database died. Quick! Change 800 configurations to get things working again!) Solution Inserting the F5 solution, the customer was able to create a single IP/port that was highly available to be used by the app tier. Using priority groups, we were able to balance traffic to each oracle node and dynamically rewrite the connect strings to match the node being used to service the request. We tested two scenarios: minimal traffic and gobs of traffic. When we failed an Oracle node under minimal traffic, the application tier was completely unaware of any change at all. No log messages, no errors, it just went along it's merry way. Running the same test with gobs of traffic (couple of GBs of transactions), the application noticed something wasn't quite right, resent the transactions that didn't make it, and happily continued. No oracle DBA intervention required. New Hotness - (aka The Magic of iRules) Configuration Use the Oracle deployment guide to ensure TCP profiles are created correctly. Also included are good procedures for building node monitors for each Oracle member. Once those are all in place, use an iRule similar to the following. This could be made more generic to accurately calculate the length of the payload replacement. The service_name and replacement SID's could also be defined as variables to make the deployment more straight forward. There's also a hack that limits the SID patching length to 1 time. In the Oracle deployment guide, the iRule is written to accommodate multiple rewrites of connect strings in a given flow. In our testing, it seemed to be adding the same offset to the list twice (which screwed things up pretty nicely). I'm not sure why that was happening, but the hack fixed it (at least in this instance). 1: when CLIENT_DATA { 2: 3: if { [TCP::payload] contains "(CONNECT_DATA=" } { 4: log local0. "Have access to TCP::Payload" 5: set service_match [regexp -all -inline -indices "\(SERVICE_NAME=some_datasource_service.world\)" [TCP::payload]] 6: log "Found a service_match = $service_match" 7: 8: set tmp [lindex $service_match 1] 9: set newservice [list $tmp] 10: 11: foreach instance $newservice { 12: log local0. "Iterating through connect strings in the payload. Raw: $instance" 13: set service_start [lindex $instance 0] 14: 15: set original_tcp_length [TCP::payload length] 16: TCP::payload replace $service_start 34 $sid 17: log local0. "Inserted SID at $service_start offset." 18: 19: TCP::payload replace 0 2 [binary format S1 [TCP::payload length]] 20: log local0. "Updated packet with new length: [TCP::payload length] - original $original_tcp_length" 21: 22: ## 23: ##set looking_for_connect [findstr [TCP::payload] "(DESCRIPTION=(ADDRESS=" 0] 24: set looking_for_connect [findstr [TCP::payload] "(DESCRIPTION" 0] 25: log local0. "Looking for connect: $looking_for_connect" 26: ##set connect_data_length [string length [findstr [TCP::payload] "(DESCRIPTION=(ADDRESS=" 0]] 27: set connect_data_length [string length [findstr [TCP::payload] "(DESCRIPTION" 0]] 28: TCP::payload replace 24 2 [binary format S1 $connect_data_length] 29: log local0. "New Oracle data length is $connect_data_length" 30: 31: } 32: } 33: if { [TCP::payload] contains "(CONNECT_DATA=" } { 34: set looking_for_connect [findstr [TCP::payload] "(DESCRIPTION" 0] 35: log local0. "2. Looking for connect: $looking_for_connect" 36: } 37: 38: TCP::release 39: TCP::collect 40: 41: } 42: when LB_SELECTED { 43: 44: log local0. "Entering LB_SELECTED" 45: if { [TCP::payload] contains "(CONNECT_DATA=" } { 46: set looking_for_connect [findstr [TCP::payload] "(DESCRIPTION" 0] 47: log local0. "1. Looking for connect: $looking_for_connect" 48: } 49: 50: 51: switch [LB::server addr] { 52: 10.10.10.152 { ; 53: set sid "SID=ORAPRIME1" 54: } 55: 10.10.10.153 { ; 56: set sid "SID=ORAPRIME2" 57: } 58: 10.10.10.154 { ; 59: set sid "SID=ORAPRIME3" 60: } 61: 10.44.44.44 { ; 62: set sid "SID=ORABACKUP" 63: } 64: } 65: TCP::collect 66: log local0. "Exiting LB_SELECTED" 67: } Related Articles DevCentral Groups - Oracle / F5 Solutions Oracle/F5 RAC Integration and DevArt - DevCentral - DevCentral ... Delivering on Oracle Cloud Oracle OpenWorld 2012: The Video Outtakes Oracle OpenWorld 2012: That's a Wrap HA between third party apps and Oracle RAC databases using f5 ... Oracle Database traffic load-balancing - DevCentral - DevCentral ... Oracle OpenWorld 2012: BIG-IP APM Integration - Oracle Access ... Technorati Tags: Oracle, RAC755Views0likes5CommentsAutomating application delivery with BIG-IP and VMware vCenter Orchestrator
Orchestration is a growing trend, whether to reduce repetitive tasks, prevent misconfiguration due to fat fingers, or allow tasks that would have been performed by specialist teams be completed instead by application administrators. The F5 plug-in for vCO aims to provide a way to perform some of the more common tasks on LTM and GTM. Some of the use cases we came up with were automating server maintenance, scaling services dynamically, and of course service provisioning. This path leads to the self-healing network ideal; where log messages or threshold alerts kick off workflows to address capacity or configuration issues, with vCenter, vCAC and other plug-ins also used to dynamically reconfigure the infrastructure. We'd love to hear about other use cases you come up with too, and of course share your workflows and comments on DevCentral. The plug-in is officially unsupported, which is to say that while we've tested it and put it through the VMware Solution Exchange certification process, we're giving it away for free and F5 support are not equipped to handle support calls on a vCO plug-in. That said if you come across problems we want to hear about them, but if they need reproducing and fixing your account team and our team in business development will probably be the ones involved. To get the plug-in and to give us comments please contact us at vco@f5.com. Getting started If you have vCenter Standard you already have vCO, whether you're using it or not. You may need to start the configuration service though, and configure and start vCO itself, I'll let VMware documentation and Google explain how to do that. If you have a more limited license of vCenter you still have vCO, but with the Essentials and Foundation you’re limited to a player mode, where you can only run pre-existing workflows rather than create and edit them. Once it's ready to go you should see the initial vCO webpage as follows, the F5 plug-in is imported from the configuration interface: Inside the configuration interface select the Plug-ins section and use the magnifying glass icon to launch the file browser, navigate to the F5 plug-in .dar file and then select Upload and Install: When imported and running the next step, still in the configuration interface, is to tell the plug-in about the LTM and GTM appliances (be they physical or virtual) you want to be able to command: It may be necessary to restart the vCO service in order for the new F5 objects to be registered. Now we're done in the configuration interface and can launch the Orchestrator client, where the next step is to import the F5 workflow actions package, select Import Package from the Run window: Again navigate to the F5 plug-in, but this time select the package file. Before you import it you will see a list of the elements in the package: Once imported you can expand the new package elements and see the new actions we now have available: Building advanced (and useful) workflows is a matter of chaining these together, which you do in the schema view: This one watches load balancing pool member statistics and if a threshold is exceeded starts additional virtual machines, or if a low watermark is reached removed them from the pool and powers them back down. Watch this space, we plan to publish more workflows and some more details on building useful schema with them. For further information: 1. The vCenter Orchestrator Plug-in for VMware vCloud Automation Center allows organizations to automate vCAC provisioning and post-provisioning tasks. With these two components, customers can leverage full bi-directional integration capabilities between vCloud Automation Center and vCenter Orchestrator. 2. Another offering is the vCenter Orchestrator Elastic Service Plug-in. This plug-in provides a foundation for the self-scaling virtual datacenter, by automatically balancing the physical resources between virtual datacenters in VMware vCloud environments. This plug-in contains a rules engine that can analyze resource usage metrics (for instance, metrics captured by vCenter Operations Manager) and make scale-up or scale-down decisions automatically. 3. The vCenter Orchestrator Plug-in for VMware Service Manager enables organizations to automate operations around Configuration, Incident, Task and Service Request management. Thanks to this plug-in, repetitive tasks such as updating an Incident or creating a Configuration Item when a new virtual machine is provisioned can now be fully automated. 4. And to help you take advantage of all of the above, the VMware Training department released over 10 self-paced vCO training videos on vmwarelearning.com available for free!489Views0likes3CommentsF5 Friday: HP Cloud Maps Help Navigate Server Flexing with BIG-IP
The economy of scale realized in enterprise cloud computing deployments is as much (if not more) about process as it is products. HP Cloud Maps simplify the former by automating the latter. When the notion of “private” or “enterprise” cloud computing first appeared, it was dismissed as being a non-viable model due to the fact that the economy of scale necessary to realize the true benefits were simply not present in the data center. What was ignored in those arguments was that the economy of scale desired by enterprises large and small was not necessarily that of technical resources, but of people. The widening gap between people and budgets and data center components was a primary cause of data center inefficiency. Enterprise cloud computing promised to relieve the increasing burden on people by moving it back to technology through automation and orchestration. As a means to achieve such a feat – and it is a non-trivial feat – required an ecosystem. No single vendor could hope to achieve the automation necessary to relieve the administrative and operational burden on enterprise IT staff because no data center is ever comprised of components provided by a single vendor. Partnerships – technological and practical partnerships – were necessary to enable the automation of processes spanning multiple data center components and achieve the economy of scale promised by enterprise cloud computing models. HP, while providing a wide variety of data center components itself, has nurtured such an ecosystem of partners. Combined with its HP Operations Orchestration, such technologically-focused partnerships have built out an ecosystem enabling the automation of common operational processes, effectively shifting the burden from people to technology, resulting in a more responsive IT organization. HP CLOUD MAPS One of the ways in which HP enables customers to take advantage of such automation capabilities is through Cloud Maps. Cloud Maps are similar in nature to F5’s Application Ready Solutions: a package of configuration templates, guides and scripts that enable repeatable architectures and deployments. Cloud Maps, according to HP’s description: HP Cloud Maps are an easy-to-use navigation system which can save you days or weeks of time architecting infrastructure for applications and services. HP Cloud Maps accelerate automation of business applications on the BladeSystem Matrix so you can reliably and consistently fast- track the implementation of service catalogs. HP Cloud Maps enable practitioners to navigate the complex operational tasks that must be accomplished to achieve even what seems like the simplest of tasks: server provisioning. It enables automation of incident resolution, change orchestration and routine maintenance tasks in the data center, providing the consistency necessary to enable more predictable and repeatable deployments and responses to data center incidents. Key components of HP Cloud Maps include: Templates for hardware and software configuration that can be imported directly into BladeSystem Matrix Tools to help guide planning Workflows and scripts designed to automate installation more quickly and in a repeatable fashion Reference whitepapers to help customize Cloud Maps for specific implementation HP CLOUD MAPS for F5 NETWORKS The partnership between F5 and HP has resulted in many data center solutions and architectures. HP’s Cloud Maps for F5 Networks today focuses on what HP calls server flexing – the automation of server provisioning and de-provisioning on-demand in the data center. It is designed specifically to work with F5 BIG-IP Local Traffic Manager (LTM) and provides the necessary configuration and deployment templates, scripts and guides necessary to implement server flexing in the data center. The Cloud Map for F5 Networks can be downloaded free of charge from HP and comprises: The F5 Networks BIG-IP reference template to be imported into HP Matrix infrastructure orchestration Workflow to be imported into HP Operations Orchestration (OO) XSL file to be installed on the Matrix CMS (Central Management Server) Perl configuration script for BIG-IP White papers with specific instructions on importing reference templates, workflows and configuring BIG-IP LTM are also available from the same site. The result is an automation providing server flexing capabilities that greatly reduces the manual intervention necessary to auto-scale and respond to capacity-induced events within the data center. Happy Flexing! Server Flexing with F5 BIG-IP and HP BladeSystem Matrix HP Cloud Maps for F5 Networks F5 Friday: The Dynamic Control Plane F5 Friday: The Evolution of Reference Architectures to Repeatable Architectures All F5 Friday Posts on DevCentral Infrastructure 2.0 + Cloud + IT as a Service = An Architectural Parfait What is a Strategic Point of Control Anyway? The F5 Dynamic Services Model Unleashing the True Potential of On-Demand IT303Views0likes1Comment
Partnerschaften für optimale Kundenlösungen
In unserer heutigen vernetzten und globalisierten Welt ist es wichtiger denn je, dass Zusammenspiel der IT-Infrastrukturkomponenten im Rechenzentrum zu optimieren. Dafür gibt es gute Gründe, senkt es sowohl die Anschaffungs- als auch die Betriebskosten. Auch in Punkto Sicherheit ist gerade in den letzten Monaten ein hohes Maß an Aufmerksamkeit gefragt, stehen hier viele Unternehmen unter Druck ihr Sicherheitskonzept zu hinterfragen und zu optimieren, um den Erfolg des Geschäfts zu schützen. Wie wir alle wissen, ist das Motto vieler CIOs „do more with less“. Somit sehen sich viele Manager der Chefetage vor die Herausforderung gestellt, kreative und neue Wege mit äquivalenten oder sogar weniger Ressourcen zu gehen. Was kann man hier also tun? Es gibt hier sicherlich viele Wege, die zum Ziel führen. Es ist jedoch offensichtlich, daß es darum geht, bestehende Systeme zu optimieren oder zu ersetzen. Die Kunst hier ist zum einen die Kosten beizubehalten oder gar zu senken und zum anderen sich für die Zukunft zu rüsten und somit vom reinen Bereitstellen der Infrastruktur zum Gestalter des Geschäfts zu werden. Ein Ansatz kann also sein, sich eine IT-Infrastruktur zu designen, deren Verwaltbarkeit einfach ist, die ein hohes Maß an Sicherheit bietet und eine erfolgreiche und schnelle Auslieferung von Daten und Anwendungen gewährleistet. Wir von F5 kooperieren mit den weltweit führenden Technologie-Unternehmen, um unseren Kunden genau solche Gesamtkonzepte anbieten zu können. Kunden profitieren von der Integration und der Interoperabilität, die sich aus dieser engen Zusammenarbeit ergibt. Wir haben auf unserer Jahreskonferenz „F5 Agility 2016“, die kürzlich in Wien stattfand unsere Top-Partner ausgezeichnet, die solche Konzepte umsetzen und den Kunden eine Lösung offerieren, die sie heutige und zukünftige Herausforderungen meistern lässt. · Dimension Data ist EMEA Partner des Jahres: Die Partnerschaft beider Unternehmen basiert auf einer 30-jährigen Erfahrung von Dimension Data im Bereich Dienstleistungen sowie der Technologie- und Produktkompetenz von F5. Dank dieser Zusammenarbeit konnten weltweit führende Organisationen einige sehr komplexe Herausforderungen im Bereich Netzwerk-Performance lösen. · Westcon EMEA ist EMEA Distributor des Jahres: Bereits zum zweiten Mal in Folge gewinnt das Unternehmen in dieser Kategorie. Basis für die Auszeichnung waren Neukundengewinne und ein starkes Umsatzwachstum. · NTT Com Security ist Customer Support Partner des Jahres: Das Unternehmen hat durch sein technisches Know-how für F5-Produkte überzeugt und damit die Erwartungen seiner Kunden übertroffen. · SFR Business Solutions ist Security Partner des Jahres: Seit mittlerweile zehn Jahren ist das Unternehmen Partner von F5 und stellt umfassende Sicherheitslösungen bereit. Weitere Gewinner sind Securelink Belgien für besondere Leistungen im Bereich Security, ATOS als MSP Partner des Jahres und BETA IT ist Innovator des Jahres. Infrasis erhält die Auszeichnung für das „Geschäft des Jahres“ und CDW Ltd ist „Rising Star of the Year“. Werfen Sie einen Blick darauf, wie wir Sie mit unseren Partnern bei der Erreichung Ihrer Ziele unterstützen können.225Views0likes0Comments